数据加载
1 | data = pd.read_csv('双十一淘宝美妆数据.csv') |
使用 pandas 读取csv
数据预处理
1 | # 对重复数据做删除处理 |
这段代码是用于数据预处理的。下面是对每个步骤的解释:
data = data.drop_duplicates(inplace=False): 这行代码用于删除数据中的重复行。drop_duplicates函数会返回一个删除了重复行的新数据集,然后将其赋值给data变量。data.shape: 这行代码用于打印数据集的形状,即行数和列数。data.reset_index(inplace=True, drop=True): 这行代码用于重置数据集的索引。reset_index函数会重置数据集的索引,并将原来的索引作为一列添加到数据集中。inplace=True表示直接修改原始数据集,drop=True表示丢弃原来的索引列。data.isnull().any(): 这行代码用于检查数据集中是否存在缺失值。isnull()函数会返回一个布尔类型的数据集,表示每个元素是否为缺失值,any()函数会检查每一列是否存在缺失值,并返回一个布尔值。data.describe(): 这行代码用于生成数据集的统计描述。describe()函数会计算每个数值列的基本统计量,如计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。mode_01 = data.sale_count.mode(): 这行代码用于计算sale_count列的众数。mode()函数会返回一个包含众数的数据集,可能有多个众数。mode_02 = data.comment_count.mode(): 这行代码用于计算comment_count列的众数,同样使用了mode()函数。data = data.fillna(0): 这行代码用于将数据集中的缺失值填充为0。fillna(0)函数会将所有缺失值替换为指定的值,这里使用的是0。data.isnull().sum(): 这行代码用于计算数据集中每列的缺失值数量。isnull().sum()函数会返回每列缺失值的数量,通过对所有列求和得到总的缺失值数量。
这些步骤可以帮助清洗数据、处理重复值和缺失值,使数据集更适合进行后续的分析和建模。
给商品名称中文分词
1 | import jieba |
这段代码使用了中文分词库jieba来对data中的title列进行分词,并将分词结果存储在title_cut列表中。然后,通过将title_cut列表赋值给data的新列item_name_cut,将分词结果添加到data数据集中。
具体的步骤如下:
import jieba: 这行代码导入了jieba库,它是一个常用的中文分词库,用于将中文文本进行分词处理。title_cut = []: 创建一个空列表title_cut,用于存储分词结果。for i in data.title:: 这行代码使用一个循环遍历data数据集中的每个title值。j = jieba.lcut(i): 这行代码使用jieba库的lcut函数对当前title值进行分词,返回一个分词后的列表,并将其赋值给变量j。title_cut.append(j): 这行代码将分词结果j添加到title_cut列表中。data['item_name_cut'] = title_cut: 这行代码将title_cut列表赋值给data数据集的新列item_name_cut,将分词结果添加到数据集中。data[['title','item_name_cut']].head(): 这行代码打印data数据集中title列和item_name_cut列的前几行数据,以检查分词结果是否正确添加到了数据集中。
技术通过使用中文分词库jieba,可以将中文文本进行分词处理,将连续的文本切分成有意义的词语,为后续的文本挖掘、自然语言处理等任务提供基础。
给商品分类
1 | data[['title','item_name_cut']].head() |
这段代码用于给商品进行分类。具体的步骤如下:
sub_type = []和main_type = []:创建两个空列表,用于存储商品的子类别和主类别。basic_config_data = """护肤品 套装 套装 ... 其他 其他 其他""":定义了一个包含商品分类信息的字符串。每一行表示一个商品类别的配置,由三个部分组成,以制表符分隔:主类别、子类别、具体的子类别列表。category_config_map = {}:创建一个空字典category_config_map,用于存储商品子类别与主类别的映射关系。for config_line in basic_config_data.split('\n')::通过对basic_config_data字符串按换行符进行分割,遍历每一行配置。basic_cateogry_list = config_line.strip().strip('\n').strip(' ').split(' '):将当前行的配置进行清理和分割,得到一个列表basic_cateogry_list,包含主类别、子类别和具体子类别列表。main_category = basic_cateogry_list[0]和sub_category = basic_cateogry_list[1]:从basic_cateogry_list提取主类别和子类别。unit_category_list = basic_cateogry_list[2:-1]:从basic_cateogry_list提取具体子类别列表。for unit_category in unit_category_list::遍历具体子类别列表。if unit_category and unit_category.strip().strip(' '):检查具体子类别是否存在且不为空。category_config_map[unit_category] = (main_category,sub_category):将具体子类别作为键,将主类别和子类别作为值,添加到category_config_map字典中,建立子类别与主类别的映射关系。category_config_map:打印category_config_map字典,以检查商品子类别与主类别的映射关系是否正确添加。
通过这段代码,可以根据配置信息将商品进行分类,并将子类别和主类别存储到对应的列表中。这样的分类信息可以用于后续的商品分析、推荐系统等任务。
没用到什么特别的技术
1 | for i in range(len(data)): |
这段代码是一个循环结构,用于将商品数据根据分类配置信息进行分类,并将分类结果存储到sub_type和main_type列表中。
具体的步骤如下:
for i in range(len(data))::通过for循环遍历data数据的索引。exist = False:初始化一个布尔变量exist,用于标记当前商品是否存在于分类配置中。for temp in data.item_name_cut[i]::通过for循环遍历当前商品的分词结果data.item_name_cut[i]中的每个词语。if temp in category_config_map::检查当前词语temp是否存在于分类配置字典category_config_map的键中。sub_type.append(category_config_map.get(temp)[1])和main_type.append(category_config_map.get(temp)[0]):如果当前词语存在于分类配置中,将对应的子类别和主类别添加到sub_type和main_type列表中。这里使用category_config_map.get(temp)来获取词语对应的主类别和子类别,并使用索引[1]和[0]来提取对应的值。exist = True:将exist变量设置为True,表示当前商品在分类配置中存在。break:跳出当前循环,结束对当前商品的词语遍历。if not exist::如果当前商品在分类配置中不存在。sub_type.append('其他')和main_type.append('其他'):将主类别和子类别都设置为’其他’,表示该商品没有匹配到任何分类配置。print(len(sub_type), len(main_type), len(data)):打印sub_type、main_type和data列表的长度,以检查分类结果的正确性。
这段代码根据商品的分词结果,在分类配置字典中查找词语对应的主类别和子类别,并将分类结果存储到sub_type和main_type列表中。如果某个商品的分词结果中的词语没有匹配到任何分类配置,那么该商品将被标记为’其他’类别。最后,通过打印列表长度的方式进行检查。
也没什么特别的技术如果循环算的话
1 | data['sub_type'] = sub_type |
这段代码用于对分类结果进行统计分析,具体进行了以下操作:
data['sub_type'] = sub_type和data['main_type'] = main_type:将分类结果存储到data数据集的sub_type和main_type列中。通过这两行代码,将分类结果与原始数据关联起来,方便后续的分析和处理。data['sub_type'].value_counts():使用value_counts()函数对data数据集中的sub_type列进行统计,计算每个子类别出现的次数。该函数会返回一个包含子类别和对应出现次数的统计结果。data['main_type'].value_counts():使用value_counts()函数对data数据集中的main_type列进行统计,计算每个主类别出现的次数。该函数会返回一个包含主类别和对应出现次数的统计结果。
通过这段代码,可以获取商品分类结果中每个子类别和主类别的出现次数统计。这对于分析商品分类的分布情况、了解主要类别和次要类别的比例以及进行后续的数据洞察和决策都是有帮助的。
也没有什么特别技术
添加是否是男的使用
1 | gender = [] |
添加一列是不是男性专用
计算销量之类的
1 | # 销售额=销售量*价格 |
data['销售额'] = data.sale_count*data.price:计算销售额,将销售量sale_count和价格price相乘,将结果存储在销售额列中。data['update_time'] = pd.to_datetime(data['update_time']):将update_time列的数据转换为日期时间格式,使用pd.to_datetime()函数进行转换。data['update_time']:打印update_time列的数据,显示转换后的日期时间格式。data = data.set_index('update_time'):将update_time列设置为数据集的新索引,通过set_index()函数实现。data['day'] = data.index.day:新增一个名为day的列,用于存储日期时间索引中的天数。del data['item_name_cut']:删除数据集中的item_name_cut列,通过del关键字实现。data.head():打印数据集的前几行,显示经过处理和转换后的数据。data.info():打印数据集的信息,包括列名、数据类型和非空值数量等。
这段代码主要用于对数据集进行预处理和转换,包括计算销售额、转换时间格式、设置新的索引、新增列、删除不需要的列等操作。这些处理和转换可以使数据集更加方便和适合进行后续的分析和计算。
技术各种数学计算
保存清理好的数据
1 | # 保存清理好的数据为Excel格式 |
到这一步终于清理好数据预处理完毕
技术pandas的保存为excel
数据分析
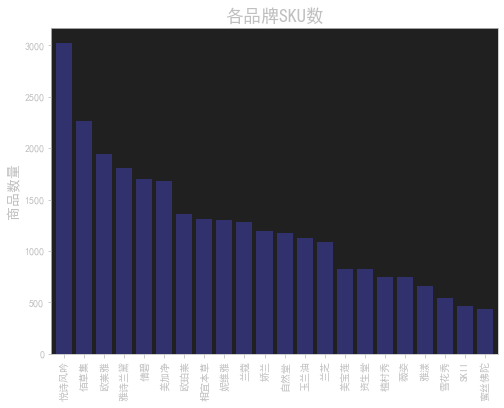
sku分析
1 | import matplotlib.pyplot as plt |
这段代码使用了Matplotlib和Seaborn库来进行数据可视化,主要实现了以下功能:
import matplotlib.pyplot as plt和import seaborn as sns:导入Matplotlib和Seaborn库,用于绘图和数据可视化。%matplotlib inline:这是一个Jupyter Notebook的魔法命令,用于在Notebook中显示Matplotlib绘制的图形。data.columns:打印数据集的列名,显示数据集中的所有列。plt.rcParams['font.sans-serif']=['SimHei']和plt.rcParams['axes.unicode_minus']=False:设置Matplotlib的字体和解决负号显示问题的配置,其中SimHei是指定的中文字体。plt.figure(figsize=(8,6)):创建一个新的图形,并指定图形的大小为8x6英寸。data['店名'].value_counts().sort_values(ascending=False).plot.bar(width=0.8,alpha=0.6,color='b'):计算每个店铺的商品数量,并将结果按照降序绘制成柱状图。data['店名'].value_counts()用于计算每个店铺的商品数量,sort_values(ascending=False)用于按照降序排序,plot.bar()用于绘制柱状图,width=0.8指定柱子的宽度,alpha=0.6指定柱子的透明度,color='b'指定柱子的颜色为蓝色。plt.title('各品牌SKU数',fontsize=18):设置图形的标题为"各品牌SKU数",并指定标题的字体大小为18。plt.ylabel('商品数量',fontsize=14):设置y轴的标签为"商品数量",并指定标签的字体大小为14。plt.show():显示绘制的图形。
这段代码的目的是绘制一个柱状图,展示各个店铺的商品数量。通过可视化数据,可以更直观地比较不同店铺之间的SKU(库存商品单位)数量差异,帮助分析和决策。
品牌销售量
1 | fig,axes = plt.subplots(1,2,figsize=(12,10)) |
这段代码使用了Matplotlib库来创建一个包含两个子图的图形,主要实现了以下功能:
-
fig,axes = plt.subplots(1,2,figsize=(12,10)):创建一个包含1行2列的图形,指定图形的大小为12x10英寸,并将返回的图形对象存储在fig和axes变量中。 -
ax1 = data.groupby('店名').sale_count.sum().sort_values(ascending=True).plot(kind='barh',ax=axes[0],width=0.6):对数据集按照店铺进行分组,计算每个店铺的总销售量,然后按照升序排序,并绘制水平条形图。kind='barh'指定绘图类型为水平条形图,ax=axes[0]指定子图的位置为第一个子图,width=0.6指定条形的宽度为0.6。绘制完成后,将返回的图形对象存储在ax1变量中。 -
ax1.set_title('品牌总销售量',fontsize=12):设置第一个子图的标题为"品牌总销售量",并指定标题的字体大小为12。 -
ax1.set_xlabel('总销售量'):设置第一个子图的x轴标签为"总销售量"。 -
ax2 = data.groupby('店名')['销售额'].sum().sort_values(ascending=True).plot(kind='barh',ax=axes[1],width=0.6):对数据集按照店铺进行分组,计算每个店铺的总销售额,然后按照升序排序,并绘制水平条形图。kind='barh'指定绘图类型为水平条形图,ax=axes[1]指定子图的位置为第二个子图,width=0.6指定条形的宽度为0.6。绘制完成后,将返回的图形对象存储在ax2变量中。 -
ax2.set_title('品牌总销售额',fontsize=12):设置第二个子图的标题为"品牌总销售额",并指定标题的字体大小为12。 -
ax2.set_xlabel('总销售额'):设置第二个子图的x轴标签为"总销售额"。 -
plt.subplots_adjust(wspace=0.4):调整子图之间的水平间距为0.4,以便更好地显示。 -
plt.show():显示绘制的图形。
这段代码的目的是绘制两个水平条形图,分别展示每个店铺的总销售量和总销售额。通过可视化数据,可以直观地比较不同店铺之间的销售情况,帮助分析和决策。
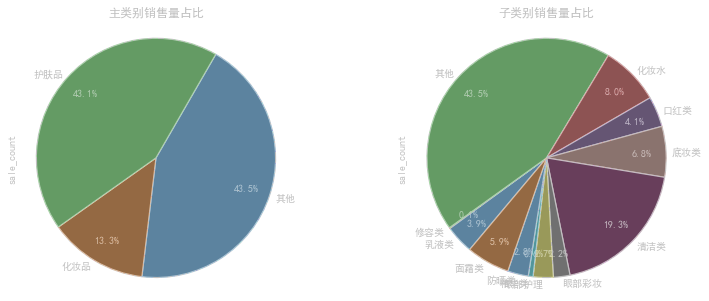
各种类占比和可视化 使用饼图
1 | fig,axes = plt.subplots(1,2,figsize=(12,5)) |
这段代码使用Matplotlib库创建了一个包含两个子图的图形,主要实现了以下功能:
fig,axes = plt.subplots(1,2,figsize=(12,5)):创建一个包含1行2列的图形,指定图形的大小为12x5英寸,并将返回的图形对象存储在fig和axes变量中。
data1 = data.groupby(‘main_type’)[‘sale_count’].sum():按照"main_type"列对数据集进行分组,计算每个主类别的销售量总和,并将结果存储在data1变量中。
ax1 = data1.plot(kind=‘pie’,ax=axes[0],autopct=‘%.1f%%’, pctdistance=0.8, labels=data1.index, labeldistance=1.05, startangle=60, radius=1.1, counterclock=False, wedgeprops={‘linewidth’: 1.2, ‘edgecolor’:‘k’}, textprops={‘fontsize’:10, ‘color’:‘k’}):绘制第一个子图,使用饼图展示每个主类别的销售量占比。kind=‘pie’指定绘图类型为饼图,ax=axes[0]指定子图的位置为第一个子图,autopct=’%.1f%%'设置百分比的显示格式,pctdistance=0.8设置百分比标签与圆心的距离,labels=data1.index指定饼图的标签为主类别的名称,labeldistance=1.05设置标签与圆心的距离,startangle=60设置饼图的初始角度,radius=1.1设置饼图的半径,counterclock=False设置饼图的绘制方向为顺时针,wedgeprops={‘linewidth’: 1.2, ‘edgecolor’:‘k’}设置饼图内外边界的属性,textprops={‘fontsize’:10, ‘color’:‘k’}设置文本标签的属性。绘制完成后,将返回的图形对象存储在ax1变量中。
ax1.set_title(‘主类别销售量占比’,fontsize=12):设置第一个子图的标题为"主类别销售量占比",并指定标题的字体大小为12。
data2 = data.groupby(‘sub_type’)[‘sale_count’].sum():按照"sub_type"列对数据集进行分组,计算每个子类别的销售量总和,并将结果存储在data2变量中。
ax2 = data2.plot(kind=‘pie’,ax=axes[1],autopct=‘%.1f%%’, pctdistance=0.8, labels=data2.index, labeldistance=1.05, startangle=230, radius=1.1, counterclock=False, wedgeprops={‘linewidth’: 1.2, ‘edgecolor’:‘k’}, textprops={‘fontsize’:10, ‘color’:‘k’}):绘制第二个子图,使用饼图展示每个子类别的销售量占比。参数的含义和设置方式与第一个子图类似,只是绘图数据和标题不同。绘制完成后,将返回的图形对象存储在ax2变量中。
ax2.set_title(‘子类别销售量占比’,fontsize=12):设置第二个子图的标题为"子类别销售量占比",并指定标题的字体大小为12。
plt.subplots_adjust(wspace=0.4):调整子图之间的水平间距为0.4,以便更好地显示。
plt.show():显示绘制的图形。
这段代码的目的是绘制两个饼图,分别展示主类别和子类别的销售量占比。通过可视化数据,可以直观地了解各个类别在销售中的贡献比例,帮助分析和决策。
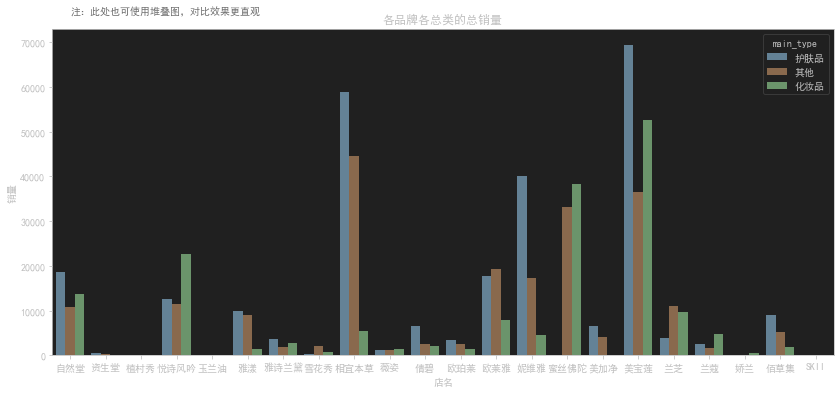
各品牌各总类的的各种属性
销量
1 | plt.figure(figsize=(14,6)) |
使用matplot创建柱状图
销售额
1 | plt.figure(figsize = (14,6)) |
重复的我就不写了
各销售物品的平均评论数
1 | plt.figure(figsize = (12,6)) |
这段代码是用来绘制一个条形图,显示各个品牌商品的平均评论数。代码的功能如下:
plt.figure(figsize=(12,6)):设置图形的大小为12英寸宽和6英寸高,创建一个新的图形窗口。data.groupby('店名').comment_count.mean():对数据集data按照 ‘店名’ 进行分组,然后计算每个组中 ‘comment_count’ 列的平均值。这将返回一个包含各个品牌的平均评论数的 Series 对象。.sort_values(ascending=False):对平均评论数进行降序排序,以便条形图能够按照从高到低的顺序显示。.plot(kind='bar', width=0.8):以条形图的形式绘制数据。参数kind='bar'指定绘制条形图,width=0.8指定条形的宽度为0.8。plt.title('各品牌商品的平均评论数'):设置图形的标题为 ‘各品牌商品的平均评论数’。plt.ylabel('评论数'):设置y轴标签为 ‘评论数’。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的品牌和评论数信息,绘制一个条形图,以展示各个品牌商品的平均评论数,并按照评论数从高到低的顺序进行排序。
当然这个使用了pandas的groupby
品牌热度的分析
1 | plt.figure(figsize=(12,10)) |
这段代码是用来绘制一个散点图,以显示不同品牌商品的销量、评论数和价格之间的关系。代码的功能如下:
plt.figure(figsize=(12,10)):设置图形的大小为12英寸宽和10英寸高,创建一个新的图形窗口。x = data.groupby('店名')['sale_count'].mean():计算每个品牌的平均销量,并将结果存储在变量x中。y = data.groupby('店名')['comment_count'].mean():计算每个品牌的平均评论数,并将结果存储在变量y中。s = data.groupby('店名')['price'].mean():计算每个品牌的平均价格,并将结果存储在变量s中。txt = data.groupby('店名').id.count().index:获取每个品牌的名称,并将结果存储在变量txt中。sns.scatterplot(x, y, size=s, hue=s, sizes=(100,1500), data=data):使用 seaborn 库的scatterplot函数绘制散点图。参数x和y分别指定 x 轴和 y 轴的数据,size=s指定散点的大小与平均价格相关,hue=s指定散点的颜色与平均价格相关,sizes=(100,1500)指定散点的大小范围,data=data指定使用的数据集。for i in range(len(txt)): plt.annotate(txt[i],xy=(x[i],y[i])):使用循环遍历每个品牌的名称,并在对应的散点上标注品牌名称。plt.ylabel('热度'):设置 y 轴标签为 ‘热度’。plt.xlabel('销量'):设置 x 轴标签为 ‘销量’。plt.legend(loc='upper left'):显示图例,将图例放置在左上角。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的品牌、销量、评论数和价格信息,绘制一个散点图,用于展示不同品牌商品之间的销量、评论数和价格的分布情况,并在散点上标注品牌名称。
使用了matplot画散点图的技术

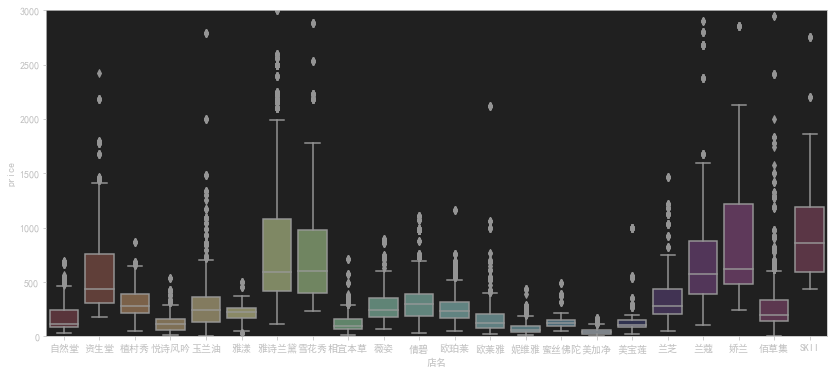
价格箱型图
1 | #查看价格的箱型图 |
这段代码是用来绘制一个箱型图,以展示不同品牌商品的价格分布情况。代码的功能如下:
plt.figure(figsize=(14,6)):设置图形的大小为14英寸宽和6英寸高,创建一个新的图形窗口。sns.boxplot(x='店名', y='price', data=data):使用 seaborn 库的boxplot函数绘制箱型图。参数x='店名'指定箱型图的横轴为品牌名称,y='price'指定箱型图的纵轴为价格,data=data指定使用的数据集。plt.ylim(0,3000):限制 y 轴的范围为0到3000,这样可以缩小 y 轴的刻度范围,使得箱型图更容易观察。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的品牌和价格信息,绘制一个箱型图,用于展示不同品牌商品的价格分布情况。通过箱型图,可以看到不同品牌商品的价格的中位数、上下四分位数、异常值等统计信息,以帮助分析价格的整体分布和离群值情况。限制 y 轴范围为0到3000是为了缩小刻度范围,更好地展示箱型图的细节。
使用了一个matplot画箱型图
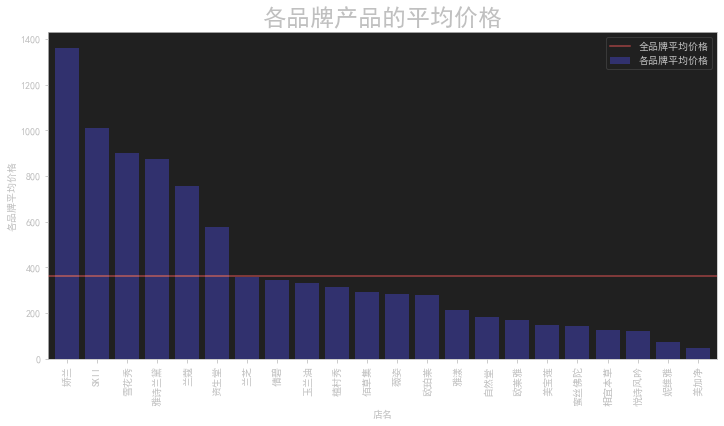
个品牌的平均价格
1 | data.groupby('店名').price.sum() |
这段代码计算了每个店铺商品的平均价格。代码的功能如下:
data.groupby('店名').price.sum():对数据集data按照 ‘店名’ 进行分组,然后计算每个组中 ‘price’ 列的总和。这将返回一个包含各个店铺商品价格总和的 Series 对象。avg_price = data.groupby('店名').price.sum() / data.groupby('店名').price.count():计算每个店铺商品的平均价格。首先,使用data.groupby('店名').price.sum()计算每个店铺商品价格的总和;然后,使用data.groupby('店名').price.count()计算每个店铺商品的数量;最后,将价格总和除以商品数量,得到每个店铺商品的平均价格。结果存储在变量avg_price中。
综合起来,这段代码的作用是根据给定数据集中的店铺和价格信息,计算每个店铺商品的平均价格,并将结果存储在变量 avg_price 中。
1 | fig = plt.figure(figsize=(12,6)) |
这段代码是用来绘制一个条形图,展示各个品牌产品的平均价格,并在图中添加全品牌平均价格的水平线。代码的功能如下:
-
fig = plt.figure(figsize=(12,6)):创建一个新的图形窗口,并设置图形的大小为12英寸宽和6英寸高。 -
avg_price.sort_values(ascending=False).plot(kind='bar', width=0.8, alpha=0.6, color='b', label='各品牌平均价格'):对平均价格进行降序排序,并以条形图的形式绘制数据。参数kind='bar'指定绘制条形图,width=0.8指定条形的宽度为0.8,alpha=0.6指定条形的透明度为0.6,color='b'指定条形的颜色为蓝色,label='各品牌平均价格'指定图例标签为’各品牌平均价格’。 -
y = data['price'].mean():计算全品牌的平均价格,并将结果存储在变量y中。 -
plt.axhline(y, 0, 5, color='r', label='全品牌平均价格'):在图中添加一条水平线,表示全品牌平均价格。y参数指定水平线的 y 坐标,0和5参数指定水平线的起始和结束位置,color='r'指定水平线的颜色为红色,label='全品牌平均价格'指定图例标签为’全品牌平均价格’。 -
plt.ylabel('各品牌平均价格'):设置 y 轴标签为’各品牌平均价格’。 -
plt.title('各品牌产品的平均价格', fontsize=24):设置图形的标题为’各品牌产品的平均价格’,并指定标题的字体大小为24。 -
plt.legend(loc='best'):显示图例,并将图例放置在最佳位置。 -
plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的品牌和价格信息,绘制一个条形图,显示各个品牌产品的平均价格,并在图中添加全品牌平均价格的水平线。图形还包括标签、标题和图例等元素,以增强可读性。
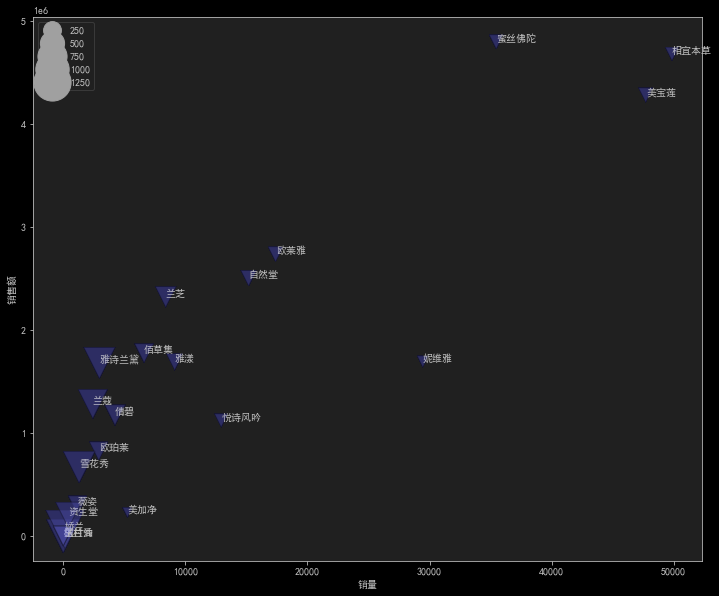
销量价格之间关系
1 | plt.figure(figsize=(12,10)) |
这段代码是用来绘制一个散点图,展示不同店铺的销售额和销量之间的关系,并在散点图上添加店铺名称的标签。代码的功能如下:
plt.figure(figsize=(12,10)):创建一个新的图形窗口,并设置图形的大小为12英寸宽和10英寸高。x = data.groupby('店名')['sale_count'].mean():计算每个店铺的销量的平均值,并将结果存储在变量x中。y = data.groupby('店名')['销售额'].mean():计算每个店铺的销售额的平均值,并将结果存储在变量y中。s = avg_price:将之前计算得到的平均价格存储在变量s中,用于设置散点的大小。txt = data.groupby('店名').id.count().index:获取每个店铺的名称,并将结果存储在变量txt中。sns.scatterplot(x, y, size=s, sizes=(100,1500), marker='v', alpha=0.5, color='b', data=data):使用 seaborn 库的scatterplot函数绘制散点图。参数x指定散点的 x 坐标为销量的平均值,y指定散点的 y 坐标为销售额的平均值,size=s指定散点的大小为平均价格,sizes=(100,1500)指定散点的大小范围为100到1500,marker='v'指定散点的形状为倒三角形,alpha=0.5指定散点的透明度为0.5,color='b'指定散点的颜色为蓝色,data=data指定使用的数据集。for i in range(len(txt))::遍历每个店铺的名称。plt.annotate(txt[i], xy=(x[i], y[i]), xytext=(x[i]+0.2, y[i]+0.2)):在散点后面添加店铺名称的标签。参数txt[i]指定标签的文本为店铺名称,xy=(x[i], y[i])指定标签的位置为对应的散点坐标,xytext=(x[i]+0.2, y[i]+0.2)指定标签文本的位置偏移量。plt.ylabel('销售额'):设置 y 轴标签为’销售额’。plt.xlabel('销量'):设置 x 轴标签为’销量’。plt.legend(loc='upper left'):显示图例,并将图例放置在左上角。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的店铺的销量和销售额信息,绘制一个散点图,显示销售额和销量之间的关系,并在散点图上添加店铺名称的标签。图形还包括标签、标题和图例等元素,以增强可读性。
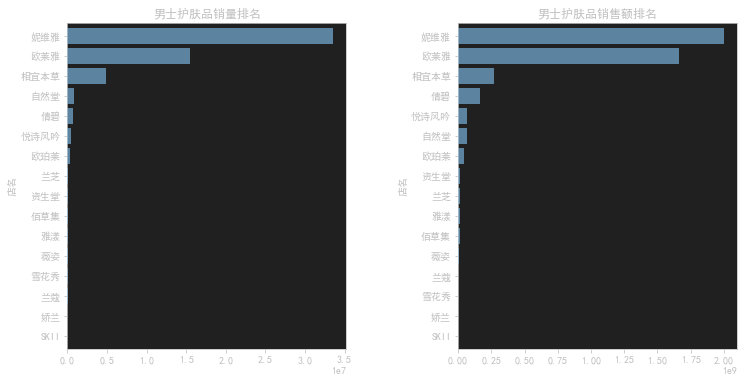
男生的销量与销售额
1 | f,[ax1,ax2]=plt.subplots(1,2,figsize=(12,6)) |
这段代码是用来绘制一个包含两个水平条形图的子图,分别展示男士护肤品销量和销售额的排名。代码的功能如下:
f, [ax1, ax2] = plt.subplots(1, 2, figsize=(12, 6)):创建一个包含两个子图的图形窗口。参数1, 2指定子图的布局为1行2列,figsize=(12, 6)指定图形的大小为12英寸宽和6英寸高。并将子图对象分别存储在ax1和ax2变量中。gender_data.groupby('店名').sale_count.sum().sort_values(ascending=True).plot(kind='barh', width=0.8, ax=ax1):对男士护肤品的销量数据进行分组,计算每个店铺的销量总和,并按照升序排序。然后以水平条形图的形式绘制数据,并将图形绘制在第一个子图ax1上。参数kind='barh'指定绘制水平条形图,width=0.8指定条形的宽度为0.8。ax1.set_title('男士护肤品销量排名'):设置第一个子图的标题为’男士护肤品销量排名’。gender_data.groupby('店名').销售额.sum().sort_values(ascending=True).plot(kind='barh', width=0.8, ax=ax2):对男士护肤品的销售额数据进行分组,计算每个店铺的销售额总和,并按照升序排序。然后以水平条形图的形式绘制数据,并将图形绘制在第二个子图ax2上。ax2.set_title('男士护肤品销售额排名'):设置第二个子图的标题为’男士护肤品销售额排名’。plt.subplots_adjust(wspace=0.4):调整两个子图之间的水平间距为0.4。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的男士护肤品的销量和销售额信息,绘制两个水平条形图的子图,分别展示男士护肤品销量和销售额的排名,并在图形中添加标题。同时通过调整子图之间的间距来改善布局。最后显示绘制的图形。
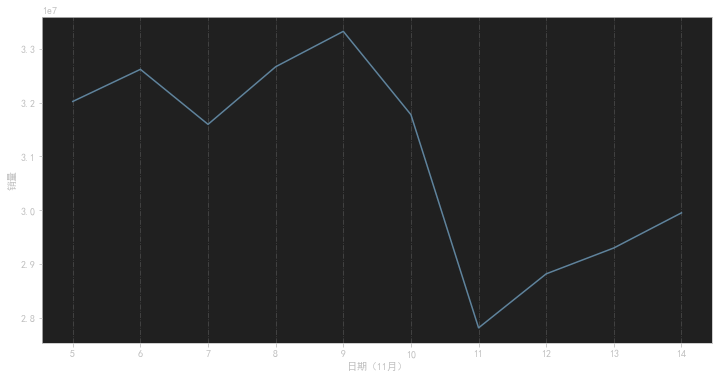
销量随时间的变化的变化
1 | from matplotlib.pyplot import MultipleLocator |
这段代码是用来绘制一个折线图,展示每天的销售量随时间的变化情况,并对图形进行一些样式设置。代码的功能如下:
-
plt.figure(figsize=(12, 6)):创建一个新的图形窗口,并设置图形的大小为12英寸宽和6英寸高。 -
day_sale = data.groupby('day')['sale_count'].sum():对数据集按照日期进行分组,并计算每天销售量的总和,并将结果存储在变量day_sale中。 -
day_sale.plot():以折线图的形式绘制每天销售量的变化情况。 -
plt.grid(linestyle="-.", color="gray", axis="x", alpha=0.5):添加网格线到图形中。参数linestyle="-."指定网格线的样式为虚线,color="gray"指定网格线的颜色为灰色,axis="x"指定只在 x 轴上显示网格线,alpha=0.5指定网格线的透明度为0.5。 -
x_major_locator = MultipleLocator(1):创建一个MultipleLocator对象,用于设置 x 轴主刻度的间隔为1。这样可以确保 x 轴上的刻度显示为整数。 -
ax = plt.gca():获取当前图形的坐标轴对象。 -
ax.xaxis.set_major_locator(x_major_locator):将 x 轴的主刻度设置为x_major_locator对象指定的刻度间隔,即每隔1个单位显示一个刻度。 -
plt.xlabel('日期(11月)'):设置 x 轴的标签为’日期(11月)'。 -
plt.ylabel('销量'):设置 y 轴的标签为’销量’。 -
plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中每天的销售量数据,绘制一个折线图,展示销售量随时间的变化情况,并对图形进行一些样式设置,如添加网格线、设置坐标轴刻度和标签等。最后显示绘制的图形。