
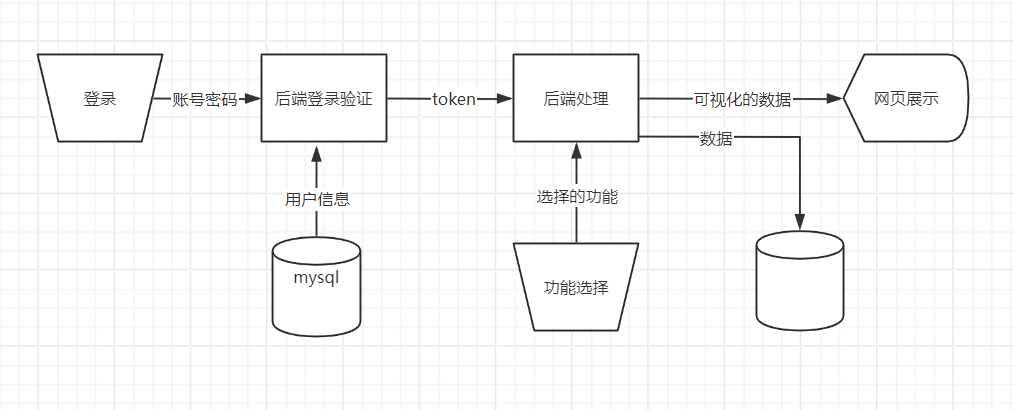
首先数据分析
数据下载
首先我们需要从hadoop下载数据集到本地电脑可以使用网页下载也可以可以使用命令行进行下载
- 命令行的下载方式是
Hadoop提供了命令行工具来进行文件的下载操作。你可以使用hadoop fs命令来执行文件下载。
下面是下载文件的命令行语法:
1 | hadoop fs -get <source> <destination> |
其中,<source>表示要下载的文件路径,可以是HDFS上的文件或目录。<destination>表示本地文件系统中保存下载文件的目标路径。
以下是使用Hadoop命令行下载文件的示例:
- 下载单个文件:
1 | hadoop fs -get hdfs://localhost:9000/path/to/source/file.txt /path/to/destination/ |
该命令将HDFS上的/path/to/source/file.txt文件下载到本地文件系统的/path/to/destination/目录下。
- 下载整个目录:
1 | hadoop fs -get hdfs://localhost:9000/path/to/source/directory/ /path/to/destination/ |
该命令将HDFS上的/path/to/source/directory/目录及其所有内容下载到本地文件系统的/path/to/destination/目录下。
请注意,-get命令将文件从HDFS下载到本地文件系统,而不是在Hadoop集群上执行。因此,你需要在运行下载命令的机器上安装Hadoop并设置正确的Hadoop配置。
此外,还可以使用其他选项来控制下载行为,例如使用-p选项来保留与源文件相同的修改时间和权限。
下载好命令行之后你就可以进入到数据预处理和数据分析的部分
美妆数据处理的代码都在ana/makeupana.ipynb中
所有以下的代码都是按顺序写的
-
首先是数据下载

这段代码使用Spark来读取本地文件并进行一些基本的数据操作和分析。
具体功能如下:
-
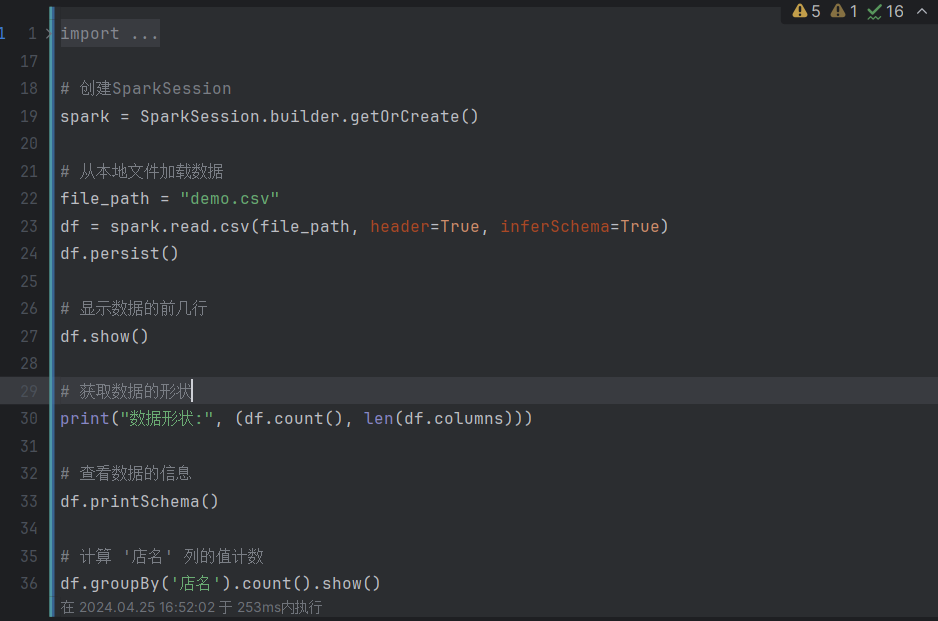
创建SparkSession:通过
SparkSession.builder.getOrCreate()创建一个SparkSession对象,用于与Spark进行交互。 -
从本地文件加载数据:使用
spark.read.csv()方法从本地文件(文件路径为demo.csv)中加载数据。header=True表示文件包含标题行,inferSchema=True表示自动推断列的数据类型。加载后的数据存储在DataFrame对象df中,并通过df.persist()方法进行持久化(缓存)。 -
显示数据的前几行:使用
df.show()方法显示DataFrame中的前几行数据,默认显示前20行。 -
获取数据的形状:通过
df.count()获取DataFrame中的行数(数据记录数),len(df.columns)获取DataFrame中的列数(字段数)。打印出数据的形状,即行数和列数。 -
查看数据的信息:使用
df.printSchema()方法打印DataFrame的结构信息,包括每个列的名称和数据类型。 -
计算 ‘店名’ 列的值计数:使用
df.groupBy('店名').count().show()方法对DataFrame按照 ‘店名’ 列进行分组,并计算每个 ‘店名’ 的出现次数。最后使用show()方法展示结果。
这段代码主要展示了使用Spark进行数据处理和分析的基本操作,包括数据加载、数据展示、数据形状统计、数据结构查看和简单的数据聚合分析。
-
数据预处理
删除缺少值
还有这段
这段代码使用了pyspark.sql.functions模块中的函数来进行一些数据处理和缺失值处理操作。
具体功能如下:
-
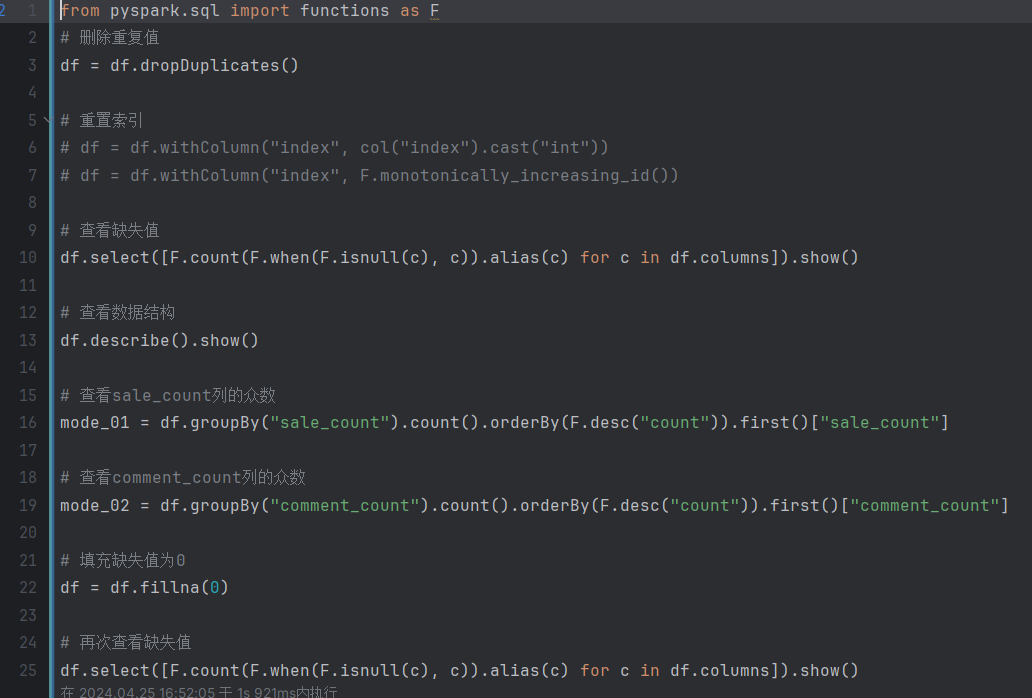
删除重复值:使用
df.dropDuplicates()方法从DataFrame中删除重复的行,保留唯一的行。 -
重置索引:这部分代码被注释掉了,可能是用于重置DataFrame的索引。使用
df.withColumn()方法可以添加一个名为"index"的列,该列的值可以通过F.monotonically_increasing_id()函数生成连续递增的唯一标识符。 -
查看缺失值:使用
df.select()方法和列表推导式来查看DataFrame中每列的缺失值数量。F.count(F.when(F.isnull(c), c))用于统计列c中的缺失值数量,并使用alias(c)为结果命名为原始列名。 -
查看数据结构:使用
df.describe().show()方法查看DataFrame的一些统计信息,包括计数、均值、标准差、最小值、最大值等。 -
查看sale_count列的众数:使用
df.groupBy("sale_count").count().orderBy(F.desc("count")).first()["sale_count"]方法计算并获取列"sale_count"中的众数(出现次数最多的值)。 -
查看comment_count列的众数:使用
df.groupBy("comment_count").count().orderBy(F.desc("count")).first()["comment_count"]方法计算并获取列"comment_count"中的众数。 -
填充缺失值为0:使用
df.fillna(0)方法将DataFrame中的缺失值填充为0。 -
再次查看缺失值:使用与第3步相同的方法来查看DataFrame中每列的缺失值数量,此时应该显示为0,因为缺失值已经被填充。
这段代码主要用于数据清洗和缺失值处理,包括删除重复值、重置索引、查看缺失值、查看数据结构、计算列的众数以及填充缺失值。
注意因为这两段是我用spark重新写过的所以我在这里解释了其意思
- 在数据分析和数据可视化之后我们会得到可视化的结果结果就是一张一张的图片,这些图片你在数据makeupana.ipyb 运行的过程中你就会看到就是那些得到的结果。
给商品名称中文分词
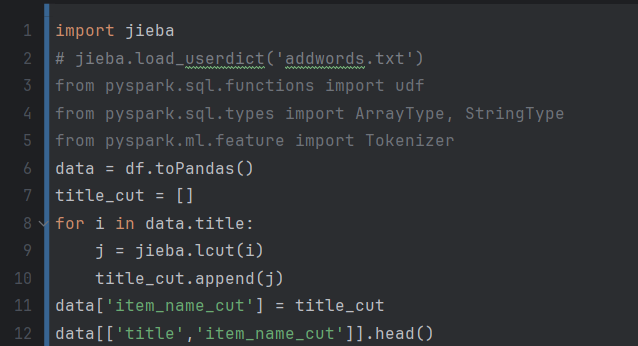
这段代码使用了中文分词库jieba来对data中的title列进行分词,并将分词结果存储在title_cut列表中。然后,通过将title_cut列表赋值给data的新列item_name_cut,将分词结果添加到data数据集中。
具体的步骤如下:
import jieba: 这行代码导入了jieba库,它是一个常用的中文分词库,用于将中文文本进行分词处理。title_cut = []: 创建一个空列表title_cut,用于存储分词结果。for i in data.title:: 这行代码使用一个循环遍历data数据集中的每个title值。j = jieba.lcut(i): 这行代码使用jieba库的lcut函数对当前title值进行分词,返回一个分词后的列表,并将其赋值给变量j。title_cut.append(j): 这行代码将分词结果j添加到title_cut列表中。data['item_name_cut'] = title_cut: 这行代码将title_cut列表赋值给data数据集的新列item_name_cut,将分词结果添加到数据集中。data[['title','item_name_cut']].head(): 这行代码打印data数据集中title列和item_name_cut列的前几行数据,以检查分词结果是否正确添加到了数据集中。
技术通过使用中文分词库jieba,可以将中文文本进行分词处理,将连续的文本切分成有意义的词语,为后续的文本挖掘、自然语言处理等任务提供基础。
给商品分类
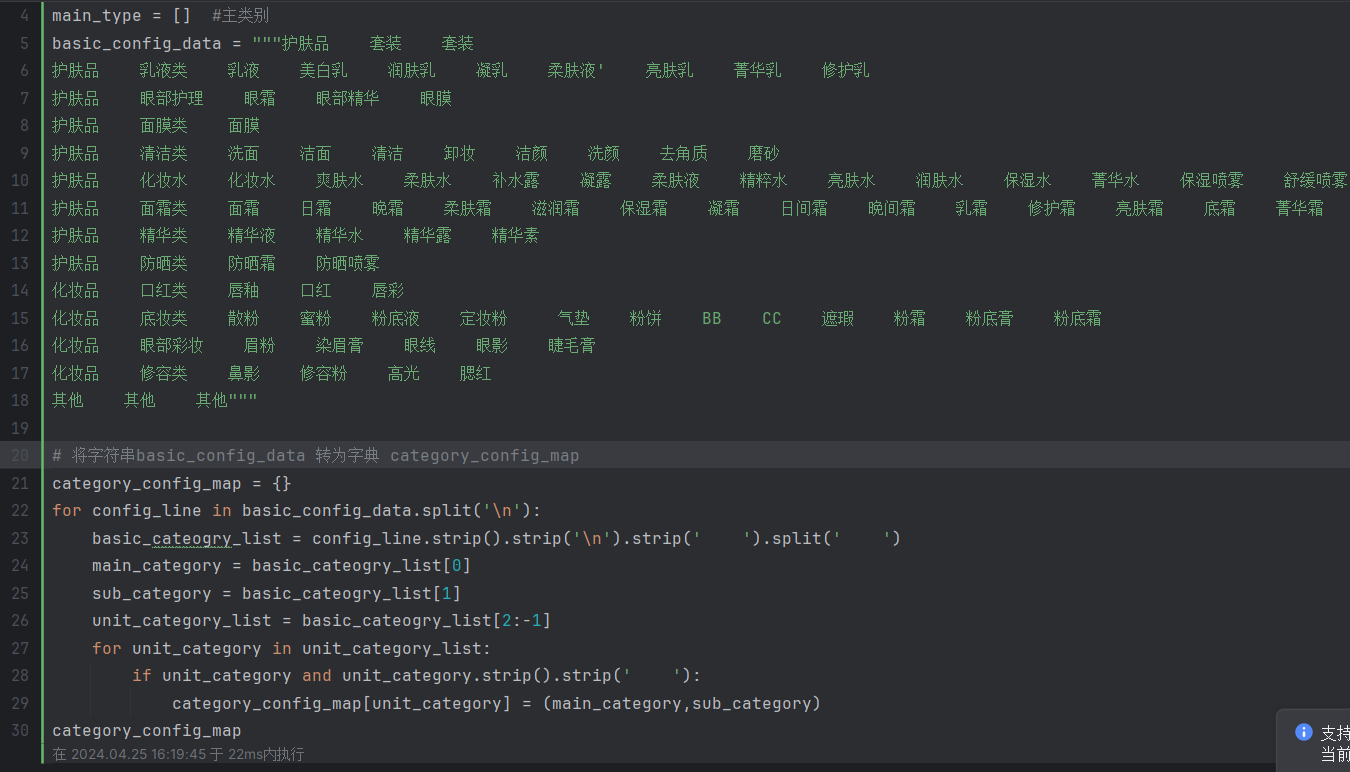
这段代码用于给商品进行分类。具体的步骤如下:
sub_type = []和main_type = []:创建两个空列表,用于存储商品的子类别和主类别。basic_config_data = """护肤品 套装 套装 ... 其他 其他 其他""":定义了一个包含商品分类信息的字符串。每一行表示一个商品类别的配置,由三个部分组成,以制表符分隔:主类别、子类别、具体的子类别列表。category_config_map = {}:创建一个空字典category_config_map,用于存储商品子类别与主类别的映射关系。for config_line in basic_config_data.split('\n')::通过对basic_config_data字符串按换行符进行分割,遍历每一行配置。basic_cateogry_list = config_line.strip().strip('\n').strip(' ').split(' '):将当前行的配置进行清理和分割,得到一个列表basic_cateogry_list,包含主类别、子类别和具体子类别列表。main_category = basic_cateogry_list[0]和sub_category = basic_cateogry_list[1]:从basic_cateogry_list提取主类别和子类别。unit_category_list = basic_cateogry_list[2:-1]:从basic_cateogry_list提取具体子类别列表。for unit_category in unit_category_list::遍历具体子类别列表。if unit_category and unit_category.strip().strip(' '):检查具体子类别是否存在且不为空。category_config_map[unit_category] = (main_category,sub_category):将具体子类别作为键,将主类别和子类别作为值,添加到category_config_map字典中,建立子类别与主类别的映射关系。category_config_map:打印category_config_map字典,以检查商品子类别与主类别的映射关系是否正确添加。
通过这段代码,可以根据配置信息将商品进行分类,并将子类别和主类别存储到对应的列表中。这样的分类信息可以用于后续的商品分析、推荐系统等任务。
没用到什么特别的技术
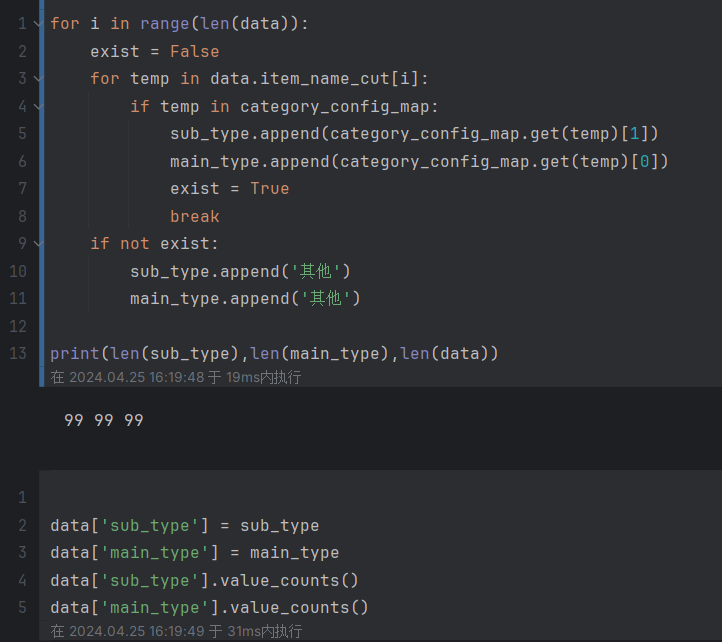
这段代码是一个循环结构,用于将商品数据根据分类配置信息进行分类,并将分类结果存储到sub_type和main_type列表中。
具体的步骤如下:
for i in range(len(data))::通过for循环遍历data数据的索引。exist = False:初始化一个布尔变量exist,用于标记当前商品是否存在于分类配置中。for temp in data.item_name_cut[i]::通过for循环遍历当前商品的分词结果data.item_name_cut[i]中的每个词语。if temp in category_config_map::检查当前词语temp是否存在于分类配置字典category_config_map的键中。sub_type.append(category_config_map.get(temp)[1])和main_type.append(category_config_map.get(temp)[0]):如果当前词语存在于分类配置中,将对应的子类别和主类别添加到sub_type和main_type列表中。这里使用category_config_map.get(temp)来获取词语对应的主类别和子类别,并使用索引[1]和[0]来提取对应的值。exist = True:将exist变量设置为True,表示当前商品在分类配置中存在。break:跳出当前循环,结束对当前商品的词语遍历。if not exist::如果当前商品在分类配置中不存在。sub_type.append('其他')和main_type.append('其他'):将主类别和子类别都设置为’其他’,表示该商品没有匹配到任何分类配置。print(len(sub_type), len(main_type), len(data)):打印sub_type、main_type和data列表的长度,以检查分类结果的正确性。
这段代码根据商品的分词结果,在分类配置字典中查找词语对应的主类别和子类别,并将分类结果存储到sub_type和main_type列表中。如果某个商品的分词结果中的词语没有匹配到任何分类配置,那么该商品将被标记为’其他’类别。最后,通过打印列表长度的方式进行检查。
也没什么特别的技术如果循环算的话
1 | data['sub_type'] = sub_type |
这段代码用于对分类结果进行统计分析,具体进行了以下操作:
data['sub_type'] = sub_type和data['main_type'] = main_type:将分类结果存储到data数据集的sub_type和main_type列中。通过这两行代码,将分类结果与原始数据关联起来,方便后续的分析和处理。data['sub_type'].value_counts():使用value_counts()函数对data数据集中的sub_type列进行统计,计算每个子类别出现的次数。该函数会返回一个包含子类别和对应出现次数的统计结果。data['main_type'].value_counts():使用value_counts()函数对data数据集中的main_type列进行统计,计算每个主类别出现的次数。该函数会返回一个包含主类别和对应出现次数的统计结果。
通过这段代码,可以获取商品分类结果中每个子类别和主类别的出现次数统计。这对于分析商品分类的分布情况、了解主要类别和次要类别的比例以及进行后续的数据洞察和决策都是有帮助的。
也没有什么特别技术
添加是否是男的使用
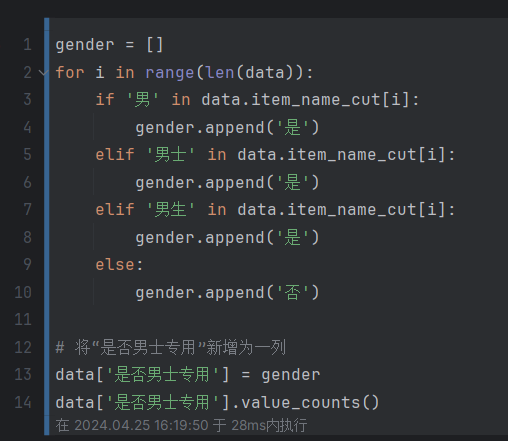
添加一列是不是男性专用
计算销量之类的
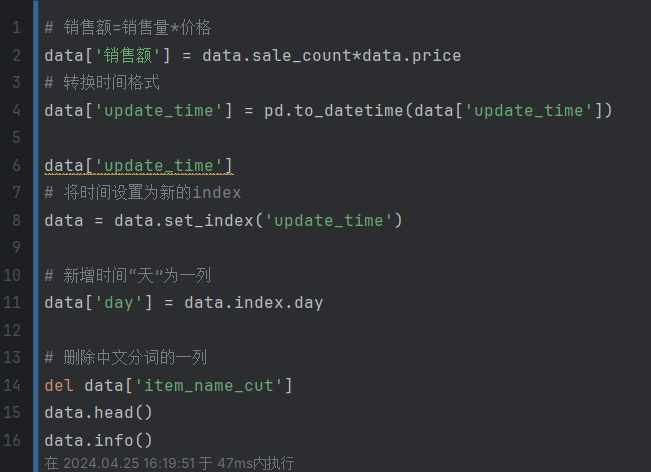
data['销售额'] = data.sale_count*data.price:计算销售额,将销售量sale_count和价格price相乘,将结果存储在销售额列中。data['update_time'] = pd.to_datetime(data['update_time']):将update_time列的数据转换为日期时间格式,使用pd.to_datetime()函数进行转换。data['update_time']:打印update_time列的数据,显示转换后的日期时间格式。data = data.set_index('update_time'):将update_time列设置为数据集的新索引,通过set_index()函数实现。data['day'] = data.index.day:新增一个名为day的列,用于存储日期时间索引中的天数。del data['item_name_cut']:删除数据集中的item_name_cut列,通过del关键字实现。data.head():打印数据集的前几行,显示经过处理和转换后的数据。data.info():打印数据集的信息,包括列名、数据类型和非空值数量等。
这段代码主要用于对数据集进行预处理和转换,包括计算销售额、转换时间格式、设置新的索引、新增列、删除不需要的列等操作。这些处理和转换可以使数据集更加方便和适合进行后续的分析和计算。
技术各种数学计算
保存清理好的数据
1 | # 保存清理好的数据为Excel格式 |
到这一步终于清理好数据预处理完毕
技术pandas的保存为excel
数据分析
sku分析
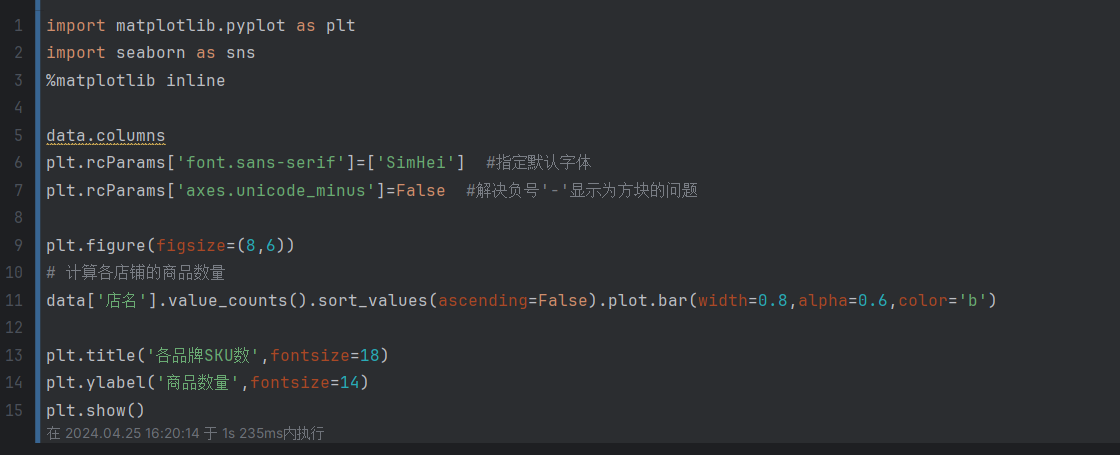
这段代码使用了Matplotlib和Seaborn库来进行数据可视化,主要实现了以下功能:
import matplotlib.pyplot as plt和import seaborn as sns:导入Matplotlib和Seaborn库,用于绘图和数据可视化。%matplotlib inline:这是一个Jupyter Notebook的魔法命令,用于在Notebook中显示Matplotlib绘制的图形。data.columns:打印数据集的列名,显示数据集中的所有列。plt.rcParams['font.sans-serif']=['SimHei']和plt.rcParams['axes.unicode_minus']=False:设置Matplotlib的字体和解决负号显示问题的配置,其中SimHei是指定的中文字体。plt.figure(figsize=(8,6)):创建一个新的图形,并指定图形的大小为8x6英寸。data['店名'].value_counts().sort_values(ascending=False).plot.bar(width=0.8,alpha=0.6,color='b'):计算每个店铺的商品数量,并将结果按照降序绘制成柱状图。data['店名'].value_counts()用于计算每个店铺的商品数量,sort_values(ascending=False)用于按照降序排序,plot.bar()用于绘制柱状图,width=0.8指定柱子的宽度,alpha=0.6指定柱子的透明度,color='b'指定柱子的颜色为蓝色。plt.title('各品牌SKU数',fontsize=18):设置图形的标题为"各品牌SKU数",并指定标题的字体大小为18。plt.ylabel('商品数量',fontsize=14):设置y轴的标签为"商品数量",并指定标签的字体大小为14。plt.show():显示绘制的图形。
这段代码的目的是绘制一个柱状图,展示各个店铺的商品数量。通过可视化数据,可以更直观地比较不同店铺之间的SKU(库存商品单位)数量差异,帮助分析和决策。
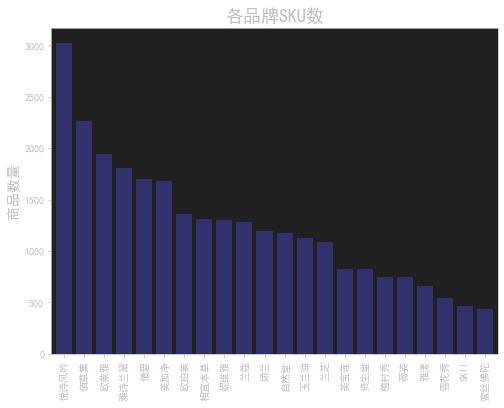
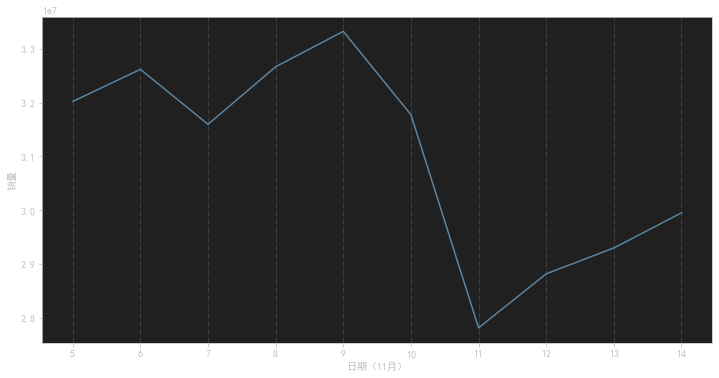
品牌销售量
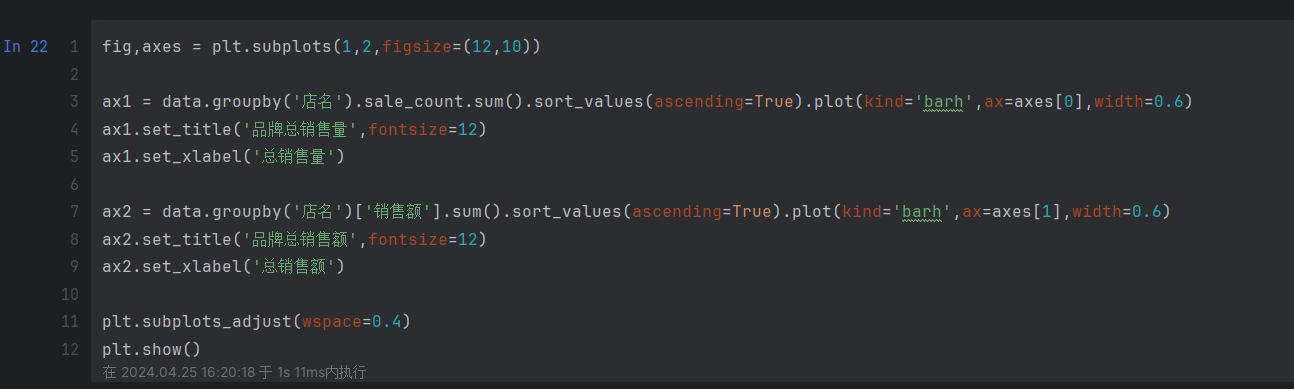
这段代码使用了Matplotlib库来创建一个包含两个子图的图形,主要实现了以下功能:
-
fig,axes = plt.subplots(1,2,figsize=(12,10)):创建一个包含1行2列的图形,指定图形的大小为12x10英寸,并将返回的图形对象存储在fig和axes变量中。 -
ax1 = data.groupby('店名').sale_count.sum().sort_values(ascending=True).plot(kind='barh',ax=axes[0],width=0.6):对数据集按照店铺进行分组,计算每个店铺的总销售量,然后按照升序排序,并绘制水平条形图。kind='barh'指定绘图类型为水平条形图,ax=axes[0]指定子图的位置为第一个子图,width=0.6指定条形的宽度为0.6。绘制完成后,将返回的图形对象存储在ax1变量中。 -
ax1.set_title('品牌总销售量',fontsize=12):设置第一个子图的标题为"品牌总销售量",并指定标题的字体大小为12。 -
ax1.set_xlabel('总销售量'):设置第一个子图的x轴标签为"总销售量"。 -
ax2 = data.groupby('店名')['销售额'].sum().sort_values(ascending=True).plot(kind='barh',ax=axes[1],width=0.6):对数据集按照店铺进行分组,计算每个店铺的总销售额,然后按照升序排序,并绘制水平条形图。kind='barh'指定绘图类型为水平条形图,ax=axes[1]指定子图的位置为第二个子图,width=0.6指定条形的宽度为0.6。绘制完成后,将返回的图形对象存储在ax2变量中。 -
ax2.set_title('品牌总销售额',fontsize=12):设置第二个子图的标题为"品牌总销售额",并指定标题的字体大小为12。 -
ax2.set_xlabel('总销售额'):设置第二个子图的x轴标签为"总销售额"。 -
plt.subplots_adjust(wspace=0.4):调整子图之间的水平间距为0.4,以便更好地显示。 -
plt.show():显示绘制的图形。
这段代码的目的是绘制两个水平条形图,分别展示每个店铺的总销售量和总销售额。通过可视化数据,可以直观地比较不同店铺之间的销售情况,帮助分析和决策。
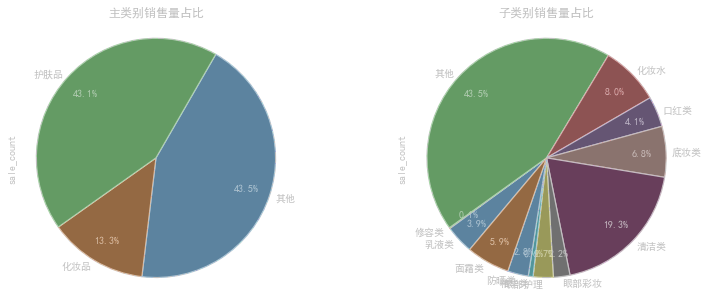
各种类占比和可视化 使用饼图
1 | fig,axes = plt.subplots(1,2,figsize=(12,5)) |
这段代码使用Matplotlib库创建了一个包含两个子图的图形,主要实现了以下功能:
fig,axes = plt.subplots(1,2,figsize=(12,5)):创建一个包含1行2列的图形,指定图形的大小为12x5英寸,并将返回的图形对象存储在fig和axes变量中。
data1 = data.groupby(‘main_type’)[‘sale_count’].sum():按照"main_type"列对数据集进行分组,计算每个主类别的销售量总和,并将结果存储在data1变量中。
ax1 = data1.plot(kind=‘pie’,ax=axes[0],autopct=‘%.1f%%’, pctdistance=0.8, labels=data1.index, labeldistance=1.05, startangle=60, radius=1.1, counterclock=False, wedgeprops={‘linewidth’: 1.2, ‘edgecolor’:‘k’}, textprops={‘fontsize’:10, ‘color’:‘k’}):绘制第一个子图,使用饼图展示每个主类别的销售量占比。kind=‘pie’指定绘图类型为饼图,ax=axes[0]指定子图的位置为第一个子图,autopct=’%.1f%%'设置百分比的显示格式,pctdistance=0.8设置百分比标签与圆心的距离,labels=data1.index指定饼图的标签为主类别的名称,labeldistance=1.05设置标签与圆心的距离,startangle=60设置饼图的初始角度,radius=1.1设置饼图的半径,counterclock=False设置饼图的绘制方向为顺时针,wedgeprops={‘linewidth’: 1.2, ‘edgecolor’:‘k’}设置饼图内外边界的属性,textprops={‘fontsize’:10, ‘color’:‘k’}设置文本标签的属性。绘制完成后,将返回的图形对象存储在ax1变量中。
ax1.set_title(‘主类别销售量占比’,fontsize=12):设置第一个子图的标题为"主类别销售量占比",并指定标题的字体大小为12。
data2 = data.groupby(‘sub_type’)[‘sale_count’].sum():按照"sub_type"列对数据集进行分组,计算每个子类别的销售量总和,并将结果存储在data2变量中。
ax2 = data2.plot(kind=‘pie’,ax=axes[1],autopct=‘%.1f%%’, pctdistance=0.8, labels=data2.index, labeldistance=1.05, startangle=230, radius=1.1, counterclock=False, wedgeprops={‘linewidth’: 1.2, ‘edgecolor’:‘k’}, textprops={‘fontsize’:10, ‘color’:‘k’}):绘制第二个子图,使用饼图展示每个子类别的销售量占比。参数的含义和设置方式与第一个子图类似,只是绘图数据和标题不同。绘制完成后,将返回的图形对象存储在ax2变量中。
ax2.set_title(‘子类别销售量占比’,fontsize=12):设置第二个子图的标题为"子类别销售量占比",并指定标题的字体大小为12。
plt.subplots_adjust(wspace=0.4):调整子图之间的水平间距为0.4,以便更好地显示。
plt.show():显示绘制的图形。
这段代码的目的是绘制两个饼图,分别展示主类别和子类别的销售量占比。通过可视化数据,可以直观地了解各个类别在销售中的贡献比例,帮助分析和决策。
使用堆叠图的表示
这段代码是用于对一份数据进行可视化的操作。:
-
第一行代码:
1
plt.figure(figsize=(14,6))
这行代码创建了一个大小为14x6的新图形,用于后续的可视化操作。
-
第二行代码:
1
sns.barplot(x='店名',y='sale_count',hue='main_type',data=data,saturation=0.75,ci=0)
这行代码使用Seaborn库的
barplot函数创建了一个条形图。x参数设置为"店名",y参数设置为"sale_count",hue参数设置为"main_type",表示将根据"main_type"的取值进行分组。data参数指定要使用的数据集,这里使用了名为data的数据集。saturation参数设置饱和度为0.75,ci参数设置为0,表示不显示误差线。 -
第三行代码:
1
plt.title('各品牌各总类的总销量')
这行代码设置了图形的标题为"各品牌各总类的总销量"。
-
第四行代码:
1
plt.ylabel('销量')
这行代码设置了纵轴的标签为"销量"。
-
第五行代码:
1
2plt.text(0,78000,'注:此处也可使用堆叠图,对比效果更直观',
verticalalignment='top', horizontalalignment='left',color='gray', fontsize=10)这行代码在图形中添加了一段文本,位于坐标(0, 78000)的位置。文本内容是"注:此处也可使用堆叠图,对比效果更直观"。
verticalalignment参数设置垂直对齐方式为"top",horizontalalignment参数设置水平对齐方式为"left",color参数设置文本颜色为灰色,fontsize参数设置文本字体大小为10。 -
第六行代码:
1
plt.show()
这行代码用于显示生成的图形。
综合起来,这段代码的目的是使用条形图对数据进行可视化,横轴表示店名,纵轴表示销售数量,颜色的不同代表不同的主要类型。图形的标题是"各品牌各总类的总销量",纵轴标签为"销量"。此外,还在图形中添加了一段注释文本,提醒读者也可使用堆叠图来观察数据的对比效果。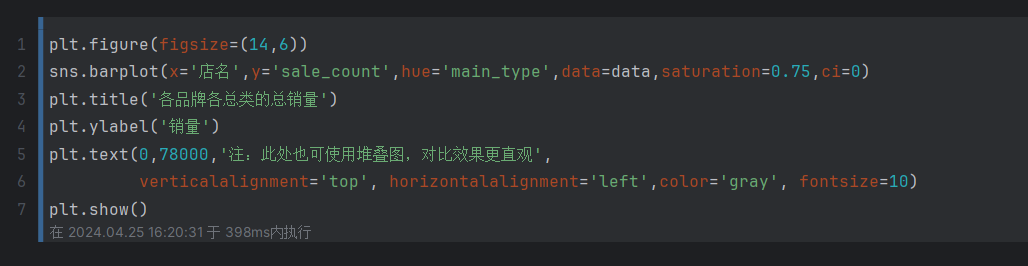
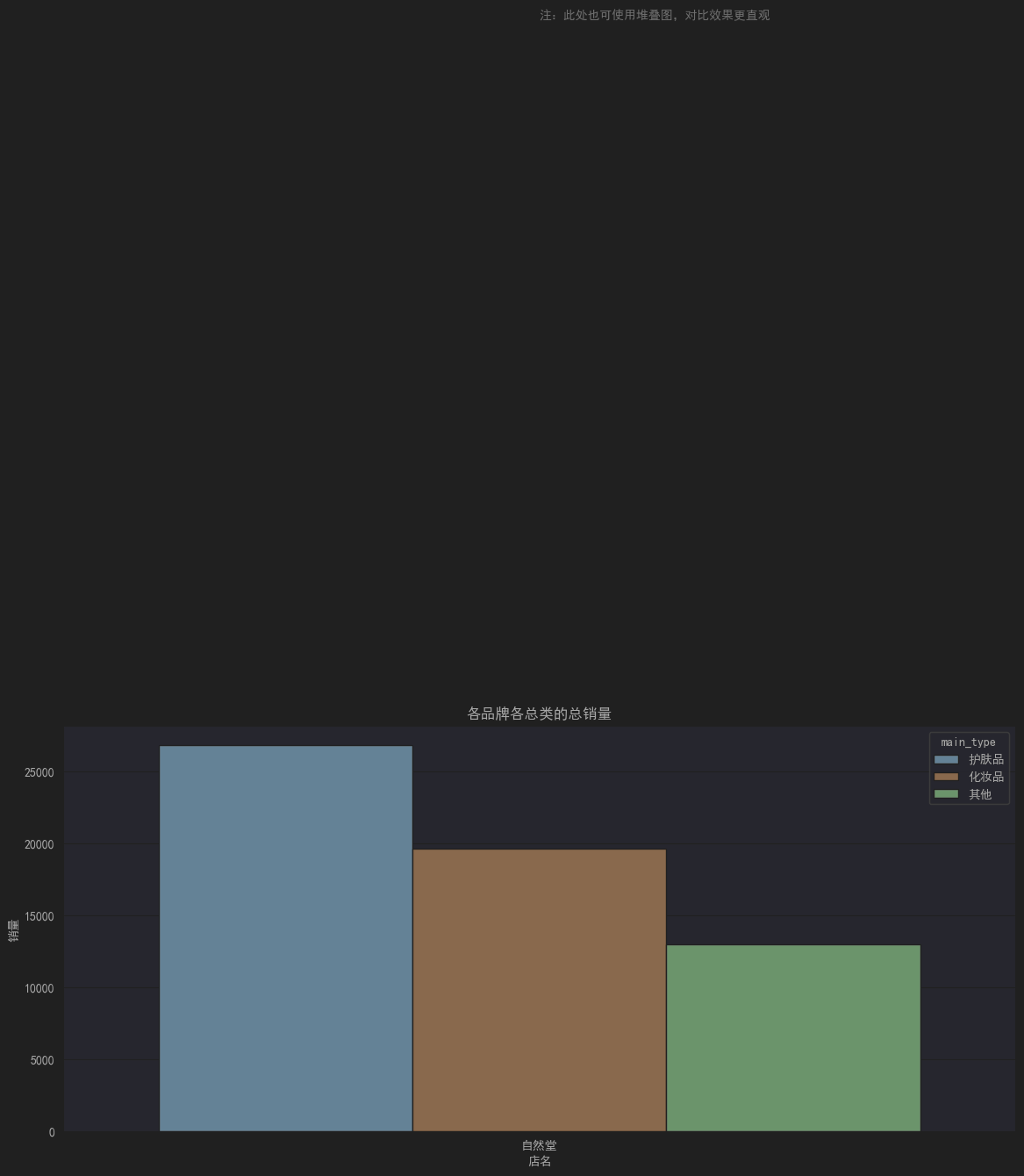
销量
使用matplot创建柱状图
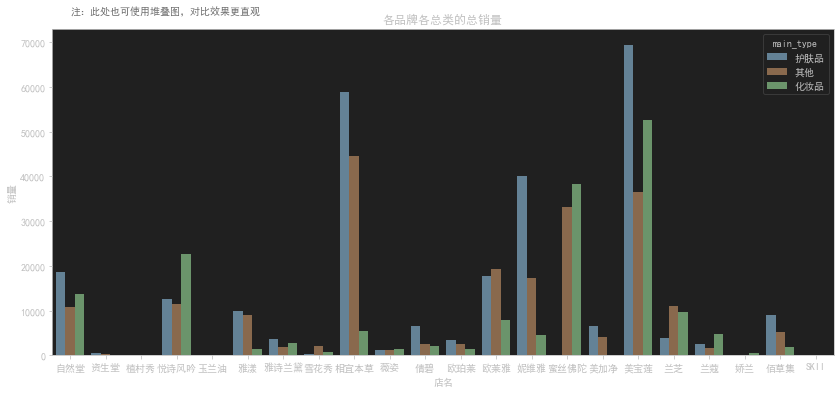
销售额
各品牌各总类总销售额
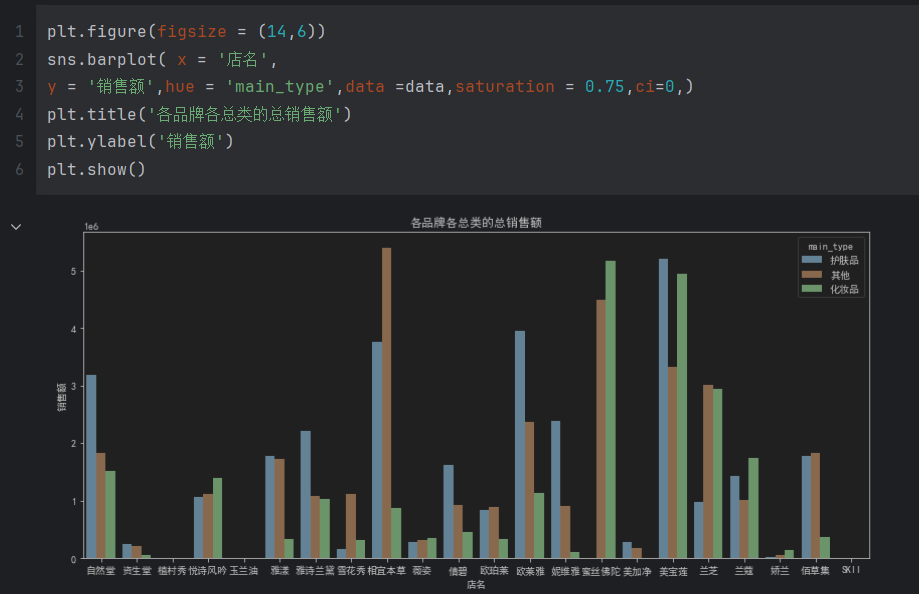
各品牌子类总销售额
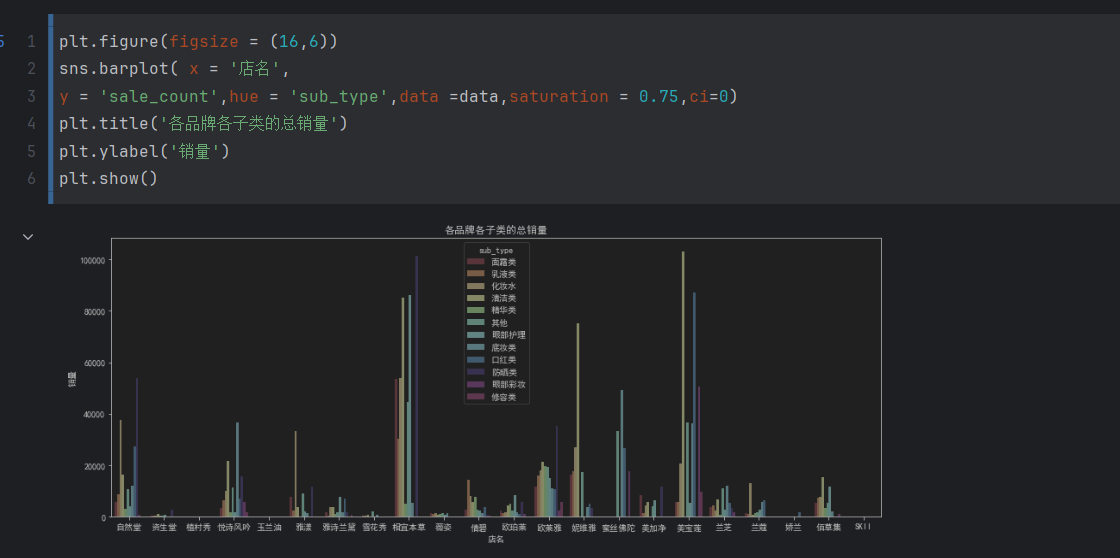
各品牌各子类总销售额
各销售物品的平均评论数

这段代码是用来绘制一个条形图,显示各个品牌商品的平均评论数。代码的功能如下:
plt.figure(figsize=(12,6)):设置图形的大小为12英寸宽和6英寸高,创建一个新的图形窗口。data.groupby('店名').comment_count.mean():对数据集data按照 ‘店名’ 进行分组,然后计算每个组中 ‘comment_count’ 列的平均值。这将返回一个包含各个品牌的平均评论数的 Series 对象。.sort_values(ascending=False):对平均评论数进行降序排序,以便条形图能够按照从高到低的顺序显示。.plot(kind='bar', width=0.8):以条形图的形式绘制数据。参数kind='bar'指定绘制条形图,width=0.8指定条形的宽度为0.8。plt.title('各品牌商品的平均评论数'):设置图形的标题为 ‘各品牌商品的平均评论数’。plt.ylabel('评论数'):设置y轴标签为 ‘评论数’。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的品牌和评论数信息,绘制一个条形图,以展示各个品牌商品的平均评论数,并按照评论数从高到低的顺序进行排序。
当然这个使用了pandas的groupby
品牌热度的分析
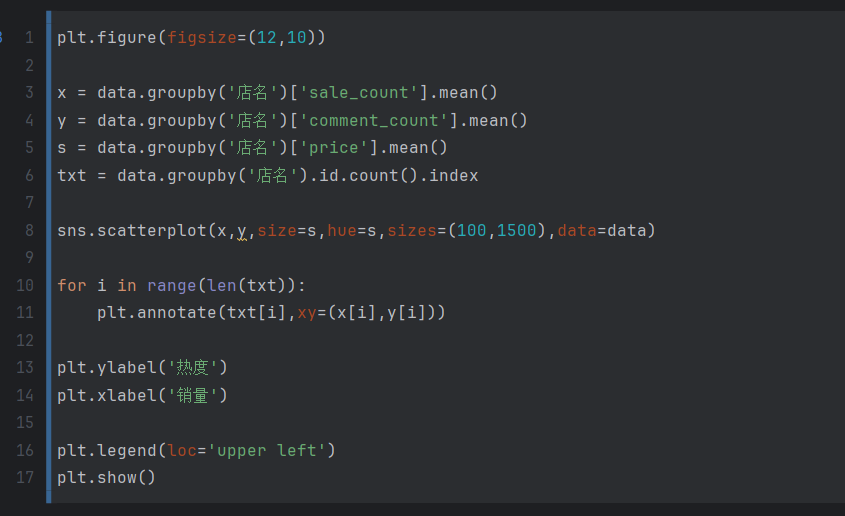
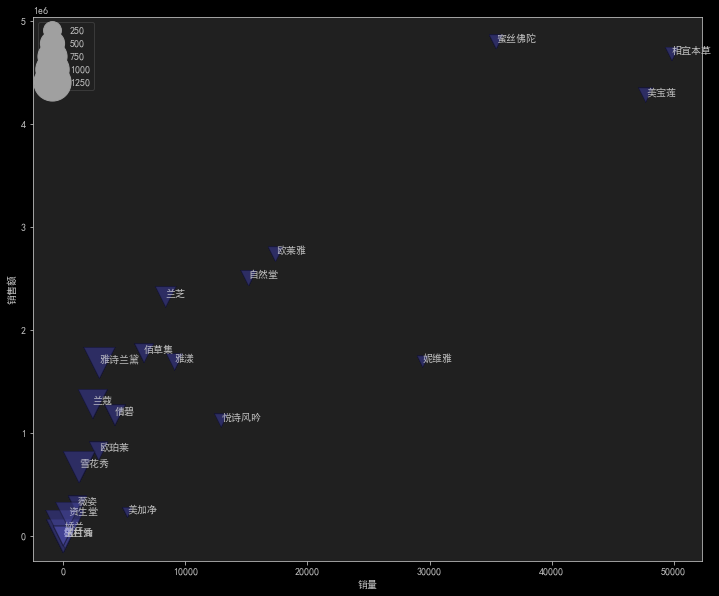
这段代码是用来绘制一个散点图,以显示不同品牌商品的销量、评论数和价格之间的关系。代码的功能如下:
plt.figure(figsize=(12,10)):设置图形的大小为12英寸宽和10英寸高,创建一个新的图形窗口。x = data.groupby('店名')['sale_count'].mean():计算每个品牌的平均销量,并将结果存储在变量x中。y = data.groupby('店名')['comment_count'].mean():计算每个品牌的平均评论数,并将结果存储在变量y中。s = data.groupby('店名')['price'].mean():计算每个品牌的平均价格,并将结果存储在变量s中。txt = data.groupby('店名').id.count().index:获取每个品牌的名称,并将结果存储在变量txt中。sns.scatterplot(x, y, size=s, hue=s, sizes=(100,1500), data=data):使用 seaborn 库的scatterplot函数绘制散点图。参数x和y分别指定 x 轴和 y 轴的数据,size=s指定散点的大小与平均价格相关,hue=s指定散点的颜色与平均价格相关,sizes=(100,1500)指定散点的大小范围,data=data指定使用的数据集。for i in range(len(txt)): plt.annotate(txt[i],xy=(x[i],y[i])):使用循环遍历每个品牌的名称,并在对应的散点上标注品牌名称。plt.ylabel('热度'):设置 y 轴标签为 ‘热度’。plt.xlabel('销量'):设置 x 轴标签为 ‘销量’。plt.legend(loc='upper left'):显示图例,将图例放置在左上角。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的品牌、销量、评论数和价格信息,绘制一个散点图,用于展示不同品牌商品之间的销量、评论数和价格的分布情况,并在散点上标注品牌名称。
使用了matplot画散点图的技术

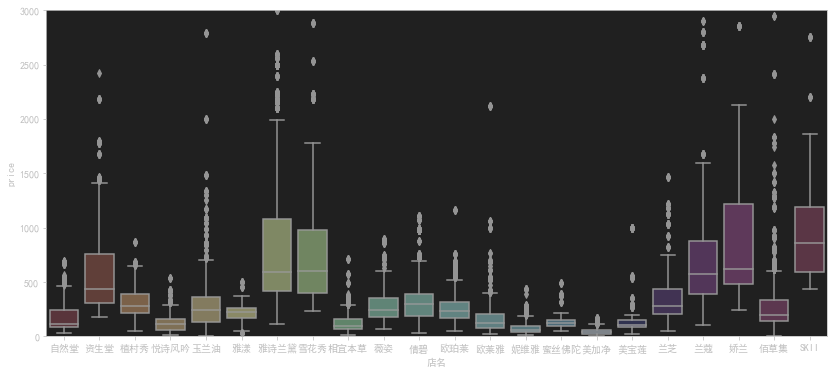
价格箱型图
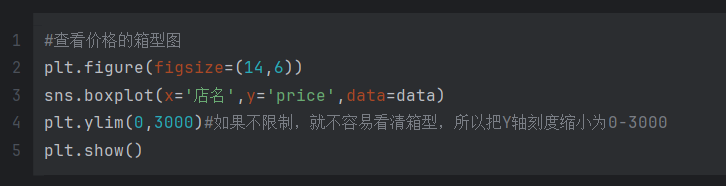
这段代码是用来绘制一个箱型图,以展示不同品牌商品的价格分布情况。代码的功能如下:
plt.figure(figsize=(14,6)):设置图形的大小为14英寸宽和6英寸高,创建一个新的图形窗口。sns.boxplot(x='店名', y='price', data=data):使用 seaborn 库的boxplot函数绘制箱型图。参数x='店名'指定箱型图的横轴为品牌名称,y='price'指定箱型图的纵轴为价格,data=data指定使用的数据集。plt.ylim(0,3000):限制 y 轴的范围为0到3000,这样可以缩小 y 轴的刻度范围,使得箱型图更容易观察。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的品牌和价格信息,绘制一个箱型图,用于展示不同品牌商品的价格分布情况。通过箱型图,可以看到不同品牌商品的价格的中位数、上下四分位数、异常值等统计信息,以帮助分析价格的整体分布和离群值情况。限制 y 轴范围为0到3000是为了缩小刻度范围,更好地展示箱型图的细节。
使用了一个matplot画箱型图
个品牌的平均价格

这段代码计算了每个店铺商品的平均价格。代码的功能如下:
data.groupby('店名').price.sum():对数据集data按照 ‘店名’ 进行分组,然后计算每个组中 ‘price’ 列的总和。这将返回一个包含各个店铺商品价格总和的 Series 对象。avg_price = data.groupby('店名').price.sum() / data.groupby('店名').price.count():计算每个店铺商品的平均价格。首先,使用data.groupby('店名').price.sum()计算每个店铺商品价格的总和;然后,使用data.groupby('店名').price.count()计算每个店铺商品的数量;最后,将价格总和除以商品数量,得到每个店铺商品的平均价格。结果存储在变量avg_price中。
综合起来,这段代码的作用是根据给定数据集中的店铺和价格信息,计算每个店铺商品的平均价格,并将结果存储在变量 avg_price 中。
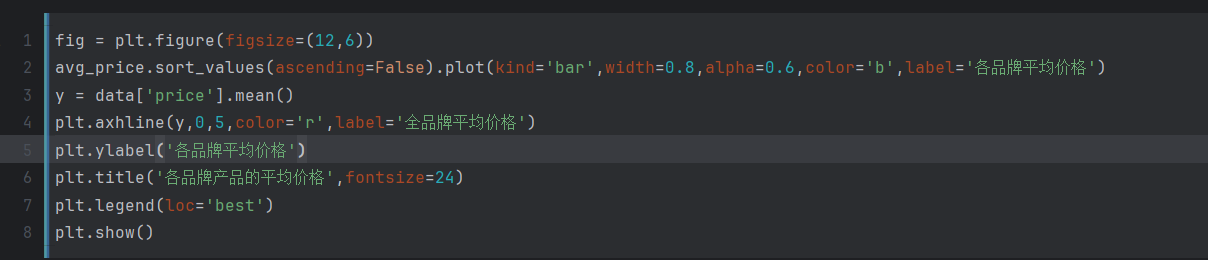
这段代码是用来绘制一个条形图,展示各个品牌产品的平均价格,并在图中添加全品牌平均价格的水平线。代码的功能如下:
-
fig = plt.figure(figsize=(12,6)):创建一个新的图形窗口,并设置图形的大小为12英寸宽和6英寸高。 -
avg_price.sort_values(ascending=False).plot(kind='bar', width=0.8, alpha=0.6, color='b', label='各品牌平均价格'):对平均价格进行降序排序,并以条形图的形式绘制数据。参数kind='bar'指定绘制条形图,width=0.8指定条形的宽度为0.8,alpha=0.6指定条形的透明度为0.6,color='b'指定条形的颜色为蓝色,label='各品牌平均价格'指定图例标签为’各品牌平均价格’。 -
y = data['price'].mean():计算全品牌的平均价格,并将结果存储在变量y中。 -
plt.axhline(y, 0, 5, color='r', label='全品牌平均价格'):在图中添加一条水平线,表示全品牌平均价格。y参数指定水平线的 y 坐标,0和5参数指定水平线的起始和结束位置,color='r'指定水平线的颜色为红色,label='全品牌平均价格'指定图例标签为’全品牌平均价格’。 -
plt.ylabel('各品牌平均价格'):设置 y 轴标签为’各品牌平均价格’。 -
plt.title('各品牌产品的平均价格', fontsize=24):设置图形的标题为’各品牌产品的平均价格’,并指定标题的字体大小为24。 -
plt.legend(loc='best'):显示图例,并将图例放置在最佳位置。 -
plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的品牌和价格信息,绘制一个条形图,显示各个品牌产品的平均价格,并在图中添加全品牌平均价格的水平线。图形还包括标签、标题和图例等元素,以增强可读性。
销量价格之间关系
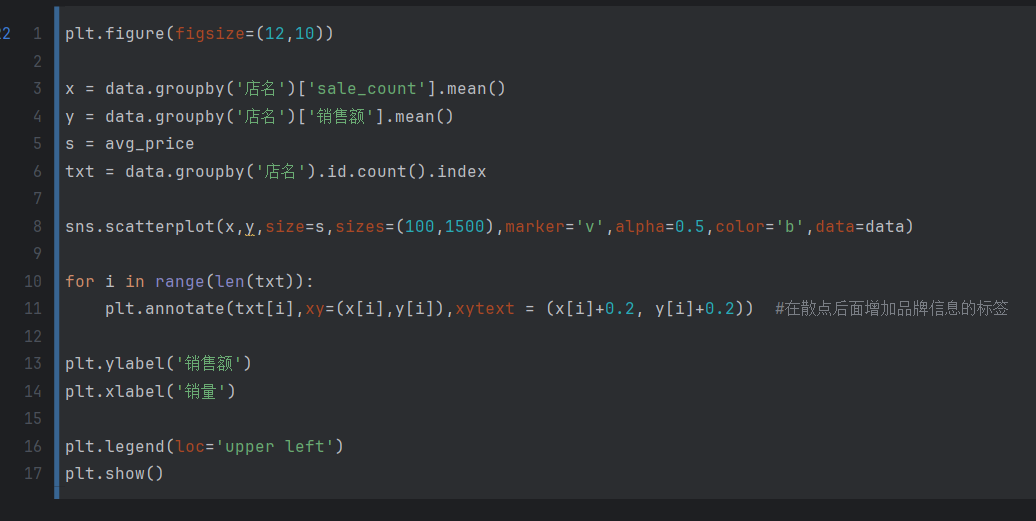
这段代码是用来绘制一个散点图,展示不同店铺的销售额和销量之间的关系,并在散点图上添加店铺名称的标签。代码的功能如下:
plt.figure(figsize=(12,10)):创建一个新的图形窗口,并设置图形的大小为12英寸宽和10英寸高。x = data.groupby('店名')['sale_count'].mean():计算每个店铺的销量的平均值,并将结果存储在变量x中。y = data.groupby('店名')['销售额'].mean():计算每个店铺的销售额的平均值,并将结果存储在变量y中。s = avg_price:将之前计算得到的平均价格存储在变量s中,用于设置散点的大小。txt = data.groupby('店名').id.count().index:获取每个店铺的名称,并将结果存储在变量txt中。sns.scatterplot(x, y, size=s, sizes=(100,1500), marker='v', alpha=0.5, color='b', data=data):使用 seaborn 库的scatterplot函数绘制散点图。参数x指定散点的 x 坐标为销量的平均值,y指定散点的 y 坐标为销售额的平均值,size=s指定散点的大小为平均价格,sizes=(100,1500)指定散点的大小范围为100到1500,marker='v'指定散点的形状为倒三角形,alpha=0.5指定散点的透明度为0.5,color='b'指定散点的颜色为蓝色,data=data指定使用的数据集。for i in range(len(txt))::遍历每个店铺的名称。plt.annotate(txt[i], xy=(x[i], y[i]), xytext=(x[i]+0.2, y[i]+0.2)):在散点后面添加店铺名称的标签。参数txt[i]指定标签的文本为店铺名称,xy=(x[i], y[i])指定标签的位置为对应的散点坐标,xytext=(x[i]+0.2, y[i]+0.2)指定标签文本的位置偏移量。plt.ylabel('销售额'):设置 y 轴标签为’销售额’。plt.xlabel('销量'):设置 x 轴标签为’销量’。plt.legend(loc='upper left'):显示图例,并将图例放置在左上角。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的店铺的销量和销售额信息,绘制一个散点图,显示销售额和销量之间的关系,并在散点图上添加店铺名称的标签。图形还包括标签、标题和图例等元素,以增强可读性。
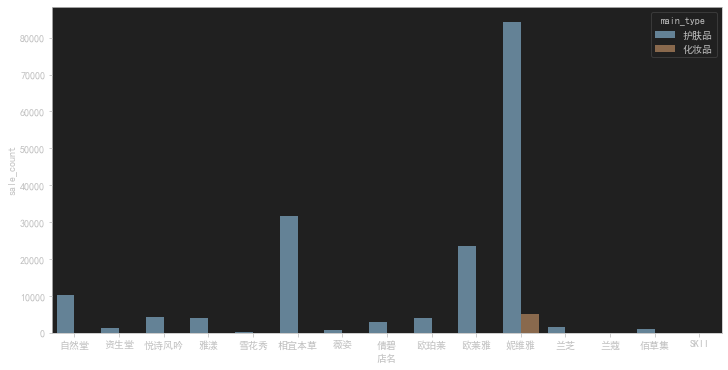
是否为男士专用

这段代码是用于对一份数据进行筛选和可视化的操作。
-
第一行代码:
1
gender_data=data[data['是否男士专用']=='是']
这行代码的目的是从名为
data的数据集中筛选出"是否男士专用"这一列的取值为"是"的数据,并将结果存储在名为gender_data的新数据集中。 -
第二行代码:
1
gender_data_1=gender_data[(gender_data.main_type =='护肤品')| (gender_data.main_type=='化妆品')]
这行代码的目的是从上一步筛选得到的
gender_data数据集中,进一步筛选出"main_type"这一列的取值为"护肤品"或"化妆品"的数据,并将结果存储在名为gender_data_1的新数据集中。 -
第三行代码:
1
plt.figure(figsize = (12,6))
这行代码创建了一个大小为12x6的新图形,用于后续的可视化操作。
-
第四行代码:
1
sns.barplot(x='店名',y='sale_count',hue='main_type',data =gender_data_1,saturation=0.75,ci=0,)
这行代码使用Seaborn库的
barplot函数创建了一个条形图。x参数设置为"店名",y参数设置为"sale_count",hue参数设置为"main_type",表示将根据"main_type"的取值进行分组。data参数指定要使用的数据集,这里使用了之前筛选得到的gender_data_1数据集。saturation参数设置饱和度为0.75,ci参数设置为0,表示不显示误差线。 -
第五行代码:
1
plt.show()
这行代码用于显示生成的图形。
综合起来,这段代码的目的是从原始数据集中筛选出"是否男士专用"为"是"的数据,并进一步筛选出"main_type"为"护肤品"或"化妆品"的数据。然后使用条形图对这些数据进行可视化,横轴表示店名,纵轴表示销售数量
男生的销量与销售额
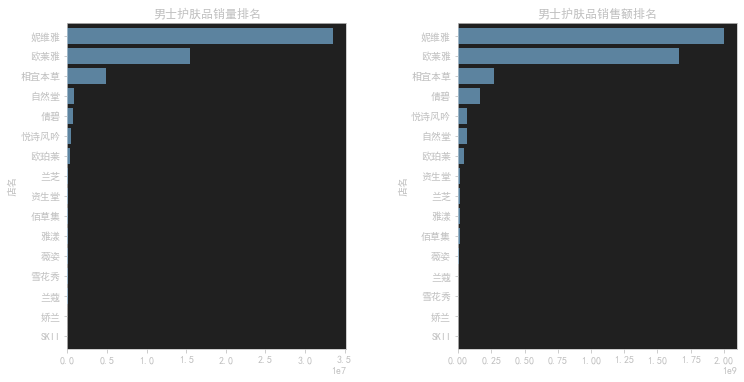
这段代码是用来绘制一个包含两个水平条形图的子图,分别展示男士护肤品销量和销售额的排名。代码的功能如下:
f, [ax1, ax2] = plt.subplots(1, 2, figsize=(12, 6)):创建一个包含两个子图的图形窗口。参数1, 2指定子图的布局为1行2列,figsize=(12, 6)指定图形的大小为12英寸宽和6英寸高。并将子图对象分别存储在ax1和ax2变量中。gender_data.groupby('店名').sale_count.sum().sort_values(ascending=True).plot(kind='barh', width=0.8, ax=ax1):对男士护肤品的销量数据进行分组,计算每个店铺的销量总和,并按照升序排序。然后以水平条形图的形式绘制数据,并将图形绘制在第一个子图ax1上。参数kind='barh'指定绘制水平条形图,width=0.8指定条形的宽度为0.8。ax1.set_title('男士护肤品销量排名'):设置第一个子图的标题为’男士护肤品销量排名’。gender_data.groupby('店名').销售额.sum().sort_values(ascending=True).plot(kind='barh', width=0.8, ax=ax2):对男士护肤品的销售额数据进行分组,计算每个店铺的销售额总和,并按照升序排序。然后以水平条形图的形式绘制数据,并将图形绘制在第二个子图ax2上。ax2.set_title('男士护肤品销售额排名'):设置第二个子图的标题为’男士护肤品销售额排名’。plt.subplots_adjust(wspace=0.4):调整两个子图之间的水平间距为0.4。plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中的男士护肤品的销量和销售额信息,绘制两个水平条形图的子图,分别展示男士护肤品销量和销售额的排名,并在图形中添加标题。同时通过调整子图之间的间距来改善布局。最后显示绘制的图形。
销量随时间的变化的变化
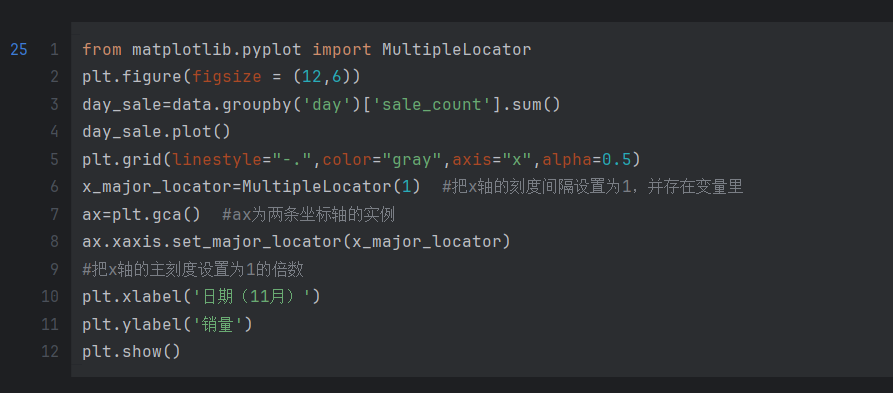
这段代码是用来绘制一个折线图,展示每天的销售量随时间的变化情况,并对图形进行一些样式设置。代码的功能如下:
-
plt.figure(figsize=(12, 6)):创建一个新的图形窗口,并设置图形的大小为12英寸宽和6英寸高。 -
day_sale = data.groupby('day')['sale_count'].sum():对数据集按照日期进行分组,并计算每天销售量的总和,并将结果存储在变量day_sale中。 -
day_sale.plot():以折线图的形式绘制每天销售量的变化情况。 -
plt.grid(linestyle="-.", color="gray", axis="x", alpha=0.5):添加网格线到图形中。参数linestyle="-."指定网格线的样式为虚线,color="gray"指定网格线的颜色为灰色,axis="x"指定只在 x 轴上显示网格线,alpha=0.5指定网格线的透明度为0.5。 -
x_major_locator = MultipleLocator(1):创建一个MultipleLocator对象,用于设置 x 轴主刻度的间隔为1。这样可以确保 x 轴上的刻度显示为整数。 -
ax = plt.gca():获取当前图形的坐标轴对象。 -
ax.xaxis.set_major_locator(x_major_locator):将 x 轴的主刻度设置为x_major_locator对象指定的刻度间隔,即每隔1个单位显示一个刻度。 -
plt.xlabel('日期(11月)'):设置 x 轴的标签为’日期(11月)'。 -
plt.ylabel('销量'):设置 y 轴的标签为’销量’。 -
plt.show():显示绘制的图形。
综合起来,这段代码的作用是根据给定数据集中每天的销售量数据,绘制一个折线图,展示销售量随时间的变化情况,并对图形进行一些样式设置,如添加网格线、设置坐标轴刻度和标签等。最后显示绘制的图形。
得到图片后可以写前端
在将这些图片粘贴到前项目中的图片文件夹
所有的分析图片会被放入makuui前端项目的assert/images中
前端将每一个分析都编写成组件
组件的位置
第一个分析在makeup-ui/src/views/system/ana1/index.vue
1 | <template> |
这段代码是一个Vue组件的代码片段,用于显示一个包含图像和文本的容器。
具体功能如下:
模板部分:
- 使用
<div class="container">定义一个容器,设置了居中对齐的样式。- 使用
<img>标签插入图像,设置了图像的宽度为50%,并使用src属性指定图像的路径为@/assets/images/ana2.jpg,alt属性为"数据展示"。脚本部分:
- 在
data属性中定义了一个imageUrl变量,值为@/assets/images/ana1.jpg,用于存储另一张图像的路径。- 定义了一个
labelText变量,值为"数据展示",用于存储文本标签的内容。样式部分:
- 使用
.container选择器定义了一个样式规则,使容器内的内容居中对齐。这段代码的主要功能是在Vue组件中创建一个包含图像和文本的容器,并通过数据绑定设置图像路径和文本内容。容器的样式设置为居中对齐。这可以用于在网页或应用程序中展示数据相关的信息或图像。
第二个分析在makeup-ui/src/views/system/ana2/index.vue
1 | <template> |
这段代码是一个Vue组件的代码片段,用于显示一个包含标题、图像和文本的容器。
具体功能如下:
-
模板部分:
- 使用
<div class="container">定义一个容器,设置了居中对齐的样式。 - 使用
<h1>标签插入一个标题,内容为"品牌销售量与销售额"。 - 使用
<img>标签插入图像,设置了图像的宽度为50%,并使用src属性指定图像的路径为@/assets/images/ana1.jpg,alt属性为"数据展示"。
- 使用
-
脚本部分:
- 在
data属性中定义了一个imageUrl变量,值为@/assets/images/ana1.jpg,用于存储图像的路径。 - 定义了一个
labelText变量,值为"数据展示",用于存储文本标签的内容。
- 在
-
样式部分:
- 使用
.container选择器定义了一个样式规则,使容器内的内容居中对齐。
- 使用
这段代码有的意思也是一样
第三个分析在makeup-ui/src/views/system/ana3/index.vue
1 | <template> |
还有第5个分析第六个都是相同的
-
router的index.js 介绍用vuerouter 将路径绑定到组件上
在makeup-ui/src/router/index.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83/**
* Note: 路由配置项
*
* hidden: true // 当设置 true 的时候该路由不会再侧边栏出现 如401,login等页面,或者如一些编辑页面/edit/1
* alwaysShow: true // 当你一个路由下面的 children 声明的路由大于1个时,自动会变成嵌套的模式--如组件页面
* // 只有一个时,会将那个子路由当做根路由显示在侧边栏--如引导页面
* // 若你想不管路由下面的 children 声明的个数都显示你的根路由
* // 你可以设置 alwaysShow: true,这样它就会忽略之前定义的规则,一直显示根路由
* redirect: noRedirect // 当设置 noRedirect 的时候该路由在面包屑导航中不可被点击
* name:'router-name' // 设定路由的名字,一定要填写不然使用<keep-alive>时会出现各种问题
* query: '{"id": 1, "name": "ry"}' // 访问路由的默认传递参数
* roles: ['admin', 'common'] // 访问路由的角色权限
* permissions: ['a:a:a', 'b:b:b'] // 访问路由的菜单权限
* meta : {
noCache: true // 如果设置为true,则不会被 <keep-alive> 缓存(默认 false)
title: 'title' // 设置该路由在侧边栏和面包屑中展示的名字
icon: 'svg-name' // 设置该路由的图标,对应路径src/assets/icons/svg
breadcrumb: false // 如果设置为false,则不会在breadcrumb面包屑中显示
activeMenu: '/system/user' // 当路由设置了该属性,则会高亮相对应的侧边栏。
}
*/
// 公共路由
export const constantRoutes = [
{
path: '/redirect',
component: Layout,
hidden: true,
children: [
{
path: '/redirect/:path(.*)',
component: () => import('@/views/redirect')
}
]
},
{
path: '/login',
component: () => import('@/views/login'),
hidden: true
},
{
path: '/register',
component: () => import('@/views/register'),
hidden: true
},
{
path: '/404',
component: () => import('@/views/error/404'),
hidden: true
},
{
path: '/401',
component: () => import('@/views/error/401'),
hidden: true
},
{
path: '',
component: Layout,
redirect: 'index',
children: [
{
path: 'index',
component: () => import('@/views/index'),
name: 'Index',
meta: { title: '首页', icon: 'dashboard', affix: true }
}
]
},
{
path: '/user',
component: Layout,
hidden: true,
redirect: 'noredirect',
children: [
{
path: 'profile',
component: () => import('@/views/system/user/profile/index'),
name: 'Profile',
meta: { title: '个人中心', icon: 'user' }
}
]
}
]
这就是router配置文件可以将之前写的组件绑定到路径上
Vue Router是Vue.js官方提供的路由管理器,用于实现前端的路由功能。它可以帮助开发者构建单页面应用(SPA)并实现页面之间的导航和跳转。
Vue Router的主要作用包括:
-
路由映射:Vue Router可以定义路由规则,将不同的URL路径映射到对应的组件,使得在不同的URL路径下展示不同的页面内容。
-
嵌套路由:Vue Router支持嵌套路由,可以实现页面的多层次嵌套和组织。
-
路由参数:通过路由参数,可以在URL中传递参数,并在组件中获取参数值,实现根据不同参数展示不同内容的功能。
-
路由导航:Vue Router提供了路由导航的功能,可以在组件中使用编程式导航(如
router.push())或者声明式导航(如<router-link>)进行页面的跳转和导航。 -
路由守卫:Vue Router提供了路由守卫的功能,可以在路由跳转前、跳转后或者路由更新时执行相应的逻辑,例如验证用户身份、权限控制、路由切换动画等。
-
历史记录管理:Vue Router可以管理浏览器的历史记录,通过使用浏览器的前进和后退按钮,可以在不刷新页面的情况下切换路由。
所以总结前端就是这样向你展示图片的。
大屏功能是可以独立的
还有一个大屏的功能
首先我们先看目录结构
再看代码
1 | #!/usr/bin/env python |
这段代码是一个Python脚本,通常用于在Django项目中启动应用程序。
具体功能如下:
-
首先,代码检查当前模块是否是主模块(即作为脚本直接执行,而不是被导入为模块)。这是通过
if __name__ == "__main__":这行代码实现的。 -
设置环境变量:代码通过
os.environ.setdefault()将环境变量DJANGO_SETTINGS_MODULE设置为makescreen.settings。这指定了Django项目的设置模块,告诉Django使用哪个配置文件来配置项目。 -
引入
execute_from_command_line函数:代码尝试导入django.core.management模块中的execute_from_command_line函数。这个函数是Django的命令行工具,用于执行各种Django管理命令。 -
执行Django命令行:最后,代码调用
execute_from_command_line(sys.argv),将命令行参数传递给execute_from_command_line函数。这样,可以在命令行中使用该脚本来执行Django的各种管理命令,例如启动开发服务器、执行数据库迁移等。
总体来说,这段代码的作用是在Django项目中启动应用程序,并通过命令行来执行各种Django管理命令。
没有什么特别每一个diango项目都有。
url.py 处于makescreen/url.py
1 | """makescreen URL Configuration |
提供的代码段是一个Django URL配置文件的片段。它包含了urlpatterns列表,用于将URL路由到Django项目中的视图函数。
在这个代码片段中,urlpatterns列表只包含了一个路径:
1 | path('admin/', admin.site.urls), |
这个路径将URL admin/ 映射到Django的管理后台。当用户访问这个URL时,将显示Django管理界面。
另外,代码中有一个if语句,它检查项目设置模块(makescreen.settings)中的DEBUG设置是否为True。如果是,urlpatterns列表将会通过调用static()函数来扩展。这个函数用于在开发期间提供静态文件的访问。它会根据设置中的STATIC_ROOT目录,添加一个用于提供静态文件(如CSS、JavaScript和图片)的URL模式。
wsgi.py 也是在makescreen文件夹中
1 | """ |
显然你已经可以看出这个makeupscreen的项目文件唯一的作用就是将
这个文件夹可以被当成静态资源访问。但是我们也是直接可以从浏览器打开不需要django
如图
开始了解怎么登录,先是前端的登录
那么前端的作用是什么前端就是为了能够实现登录功能
当你在登录的时候你会发现当你不登录你就会自动的跳回登录界面,这是因为有拦截器的存在。
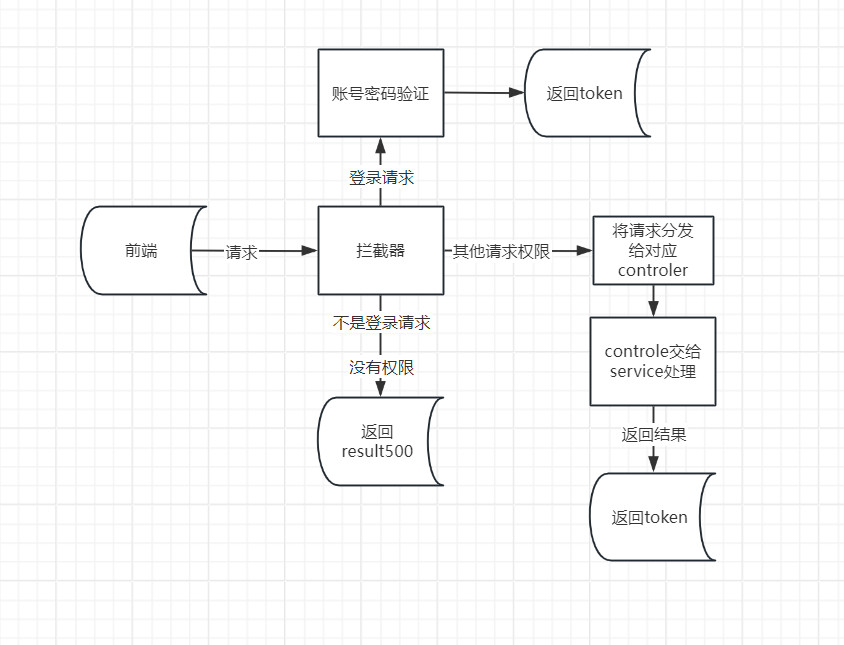
结合这两张图
整体代码
-
第一张图的登录现在是在前端这一块的代码是在makeup-ui/src/views/login.vue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158<template>
<div class="login">
<el-form ref="loginForm" :model="loginForm" :rules="loginRules" class="login-form">
<h3 class="title">淘宝美妆销售数据分析及可视化</h3>
<el-form-item prop="username">
<el-input
v-model="loginForm.username"
type="text"
auto-complete="off"
placeholder="账号"
>
<svg-icon slot="prefix" icon-class="user" class="el-input__icon input-icon" />
</el-input>
</el-form-item>
<el-form-item prop="password">
<el-input
v-model="loginForm.password"
type="password"
auto-complete="off"
placeholder="密码"
@keyup.enter.native="handleLogin"
>
<svg-icon slot="prefix" icon-class="password" class="el-input__icon input-icon" />
</el-input>
</el-form-item>
<el-form-item prop="code" v-if="captchaEnabled">
<el-input
v-model="loginForm.code"
auto-complete="off"
placeholder="验证码"
style="width: 63%"
@keyup.enter.native="handleLogin"
>
<svg-icon slot="prefix" icon-class="validCode" class="el-input__icon input-icon" />
</el-input>
<div class="login-code">
<img :src="codeUrl" @click="getCode" class="login-code-img"/>
</div>
</el-form-item>
<el-checkbox v-model="loginForm.rememberMe" style="margin:0px 0px 25px 0px;">记住密码</el-checkbox>
<el-form-item style="width:100%;">
<el-button
:loading="loading"
size="medium"
type="primary"
style="width:100%;"
@click.native.prevent="handleLogin"
>
<span v-if="!loading">登 录</span>
<span v-else>登 录 中...</span>
</el-button>
<div style="float: right;" v-if="register">
<router-link class="link-type" :to="'/register'">立即注册</router-link>
</div>
</el-form-item>
</el-form>
<!-- 底部 -->
<div class="el-login-footer">
<span>Copyright © 2018-2023 ruoyi.vip All Rights Reserved.</span>
</div>
</div>
</template>
<script>
import { getCodeImg } from "@/api/login";
import Cookies from "js-cookie";
import { encrypt, decrypt } from '@/utils/jsencrypt'
export default {
name: "Login",
data() {
return {
codeUrl: "",
loginForm: {
username: "admin",
password: "admin123",
rememberMe: false,
code: "",
uuid: ""
},
loginRules: {
username: [
{ required: true, trigger: "blur", message: "请输入您的账号" }
],
password: [
{ required: true, trigger: "blur", message: "请输入您的密码" }
],
code: [{ required: true, trigger: "change", message: "请输入验证码" }]
},
loading: false,
// 验证码开关
captchaEnabled: true,
// 注册开关
register: false,
redirect: undefined
};
},
watch: {
$route: {
handler: function(route) {
this.redirect = route.query && route.query.redirect;
},
immediate: true
}
},
created() {
this.getCode();
this.getCookie();
},
methods: {
getCode() {
getCodeImg().then(res => {
this.captchaEnabled = res.captchaEnabled === undefined ? true : res.captchaEnabled;
if (this.captchaEnabled) {
this.codeUrl = "data:image/gif;base64," + res.img;
this.loginForm.uuid = res.uuid;
}
});
},
getCookie() {
const username = Cookies.get("username");
const password = Cookies.get("password");
const rememberMe = Cookies.get('rememberMe')
this.loginForm = {
username: username === undefined ? this.loginForm.username : username,
password: password === undefined ? this.loginForm.password : decrypt(password),
rememberMe: rememberMe === undefined ? false : Boolean(rememberMe)
};
},
handleLogin() {
this.$refs.loginForm.validate(valid => {
if (valid) {
this.loading = true;
if (this.loginForm.rememberMe) {
Cookies.set("username", this.loginForm.username, { expires: 30 });
Cookies.set("password", encrypt(this.loginForm.password), { expires: 30 });
Cookies.set('rememberMe', this.loginForm.rememberMe, { expires: 30 });
} else {
Cookies.remove("username");
Cookies.remove("password");
Cookies.remove('rememberMe');
}
this.$store.dispatch("Login", this.loginForm).then(() => {
this.$router.push({ path: this.redirect || "/" }).catch(()=>{});
}).catch(() => {
this.loading = false;
if (this.captchaEnabled) {
this.getCode();
}
});
}
});
}
}
};
</script>
这段代码是一个Vue.js组件,表示一个登录页面。下面是对代码的解释:
-
模板部分(template):这部分定义了登录页面的HTML结构,使用了Element UI库的组件来构建表单和按钮等元素。登录表单包括账号、密码和验证码等输入框,以及记住密码的复选框和登录按钮。底部显示了版权信息。
-
脚本部分(script):这部分是Vue组件的JavaScript代码。其中,
getCodeImg和encrypt、decrypt是从其他模块中导入的函数。这个组件的名称是Login,数据(data)部分定义了登录表单的初始值和校验规则,以及其他需要的变量。created方法在组件创建时被调用,用于获取验证码并获取保存的cookie。getCode方法用于获取验证码的图片,并根据接口返回的数据判断是否显示验证码输入框。getCookie方法用于获取保存的cookie值,并将其赋值给登录表单。handleLogin方法用于处理登录操作,首先校验表单数据的有效性,然后根据是否记住密码设置cookie,最后调用Loginaction进行登录,成功后跳转到指定页面。
这段代码使用了Element UI组件库来构建登录页面,并使用axios库来发送HTTP请求。它还使用了一些辅助函数和工具,如获取验证码图片、加密和解密等。
具体代码
1 | handleLogin() { |
这段代码是handleLogin方法,用于处理用户登录操作。下面是对代码的解释:
-
this.$refs.loginForm.validate:使用this.$refs来访问组件中的具名引用(ref),loginForm是表单组件的引用名称。validate是Element UI表单组件提供的方法,用于校验表单字段的有效性。它接受一个回调函数作为参数,回调函数会在校验完成后被调用,并传入一个布尔值valid表示表单是否有效。 -
if (valid):如果表单校验有效,则执行以下代码块。 -
this.loading = true:将loading设置为true,用于显示登录按钮的加载状态。 -
if (this.loginForm.rememberMe):如果用户选择了"记住密码"选项,则执行以下代码块。Cookies.set("username", this.loginForm.username, { expires: 30 }):使用Cookies工具函数设置一个名为"username"的cookie,保存用户输入的用户名,有效期为30天。Cookies.set("password", encrypt(this.loginForm.password), { expires: 30 }):使用encrypt函数对用户输入的密码进行加密,并将加密后的密码保存在名为"password"的cookie中,有效期为30天。Cookies.set('rememberMe', this.loginForm.rememberMe, { expires: 30 }):保存"rememberMe"选项的值到名为"rememberMe"的cookie中,有效期为30天。
-
else:如果用户没有选择"记住密码"选项,则执行以下代码块。Cookies.remove("username"):移除名为"username"的cookie。Cookies.remove("password"):移除名为"password"的cookie。Cookies.remove('rememberMe'):移除名为"rememberMe"的cookie。
-
this.$store.dispatch("Login", this.loginForm):通过this.$store.dispatch方法触发名为"Login"的action,并传递this.loginForm作为参数。这个action会处理用户登录逻辑,发送登录请求等。 -
.then(() => { this.$router.push({ path: this.redirect || "/" }).catch(()=>{}); }):如果登录成功,通过this.$router.push方法将用户重定向到指定的路径(this.redirect)或默认路径"/"。.catch(()=>{})用于捕获可能的重定向错误,避免控制台抛出异常。 -
.catch(() => { this.loading = false; if (this.captchaEnabled) { this.getCode(); } }):如果登录失败,执行以下代码块。this.loading = false:将loading设置为false,用于取消登录按钮的加载状态。if (this.captchaEnabled):如果验证码开关为打开状态,则执行以下代码块。this.getCode():重新获取验证码图片。
这段代码的功能是校验表单的有效性,根据用户选择的"记住密码"选项设置相应的cookie,然后触发登录动作,并根据登录结果进行相应的处理,包括重定向和验证码的刷新。
1 | getCode() { |
这段代码包含了两个方法:getCode()和getCookie(),下面是对它们的解释:
-
getCode()方法用于获取验证码图片,并更新相关的状态和数据。getCodeImg():调用getCodeImg()函数来获取验证码图片,返回一个Promise对象。.then(res => { ... }):当获取验证码成功后,执行回调函数,回调函数的参数res包含了获取到的数据。this.captchaEnabled = res.captchaEnabled === undefined ? true : res.captchaEnabled;:根据返回的数据中的captchaEnabled字段判断是否启用验证码。如果captchaEnabled字段未定义,将this.captchaEnabled设置为true,否则根据返回值来设置。if (this.captchaEnabled) { ... }:如果验证码启用,执行以下代码块。this.codeUrl = "data:image/gif;base64," + res.img;:将获取到的验证码图片数据拼接成Base64格式的URL,并赋值给this.codeUrl,用于在页面上显示验证码图片。this.loginForm.uuid = res.uuid;:将返回的验证码UUID赋值给登录表单中的uuid字段。
-
getCookie()方法用于获取保存的cookie,并将其值赋给登录表单的相应字段。const username = Cookies.get("username");:使用Cookies.get()函数获取名为"username"的cookie的值,并将其赋给变量username。const password = Cookies.get("password");:使用Cookies.get()函数获取名为"password"的cookie的值,并将其赋给变量password。const rememberMe = Cookies.get('rememberMe'):使用Cookies.get()函数获取名为"rememberMe"的cookie的值,并将其赋给变量rememberMe。this.loginForm = { ... }:将获取到的cookie值更新到登录表单的相应字段。username === undefined ? this.loginForm.username : username:如果username为undefined,则使用登录表单中的username字段的初始值,否则使用username的值。password === undefined ? this.loginForm.password : decrypt(password):如果password为undefined,则使用登录表单中的password字段的初始值,否则使用password的值。注意,这里使用了decrypt()函数对保存的加密密码进行解密。rememberMe === undefined ? false : Boolean(rememberMe):如果rememberMe为undefined,则设置为false,否则将rememberMe转换为对应的布尔值。
这两个方法分别用于获取验证码图片和获取保存的cookie,并更新相关的状态和数据,以便在登录页面中显示验证码图片和填充保存的用户名和密码(如果存在)。
到现在前端登录的功能的过程就是会将你的请求发送给后端。
请求到后端怎么处理登录
后端首先第一步要经历拦截器
先到拦截器
什么是springboot的拦截器
在Spring Boot中,拦截器(Interceptor)是一种用于拦截请求并在处理请求之前或之后执行一些操作的机制。拦截器是Spring框架提供的一种增强控制器功能的方式,它可以用于实现诸如身份验证、日志记录、性能监控、请求处理前后的预处理和后处理等功能。
拦截器是基于Spring框架的AOP(面向切面编程)思想实现的。它通过定义拦截器类并将其配置到Spring应用程序中,使得拦截器可以在请求被处理前或处理后介入请求的处理流程。
在Spring Boot中,创建一个拦截器需要实现HandlerInterceptor接口,并实现其中的方法。主要的方法包括:
-
preHandle:在请求处理之前被调用。可以进行一些预处理操作,如身份验证、权限检查等。如果该方法返回false,则请求将被拦截,后续的处理流程将被终止。 -
postHandle:在请求处理之后、视图渲染之前被调用。可以对请求处理结果进行一些处理或修改。 -
afterCompletion:在整个请求处理完成后被调用。可以进行一些清理操作或资源释放等。
拦截器可以通过配置来应用于特定的请求路径或URL模式。在Spring Boot中,可以通过实现WebMvcConfigurer接口中的addInterceptors方法,或使用@Configuration注解和WebMvcConfigurerAdapter类来进行拦截器的配置。
所以你后端项目的拦截器在src/main/java/makeup/framework/config/ResourcesConfig.java
1 | package makeup.framework.config; |
添加的拦截器的具体代码如下src/main/java/makeup/framework/interceptor/RepeatSubmitInterceptor.java
1 | package makeup.framework.interceptor; |
这段代码是一个防止重复提交的拦截器实现,它是一个抽象类 RepeatSubmitInterceptor,实现了 Spring Framework 的 HandlerInterceptor 接口。
主要功能如下:
- 在
preHandle方法中,拦截器首先判断处理请求的方法是否带有@RepeatSubmit注解,如果有该注解,则表示需要进行重复提交的验证。 - 如果请求方法带有
@RepeatSubmit注解,则调用抽象方法isRepeatSubmit,由子类实现具体的防重复提交的规则。 isRepeatSubmit方法接收请求信息和@RepeatSubmit注解作为参数,子类需要根据具体需求来判断当前请求是否属于重复提交。- 如果
isRepeatSubmit方法返回true,表示请求是重复提交,拦截器会返回一个错误的响应给客户端,响应内容为一个包含错误信息的 JSON 对象。 - 如果
isRepeatSubmit方法返回false,表示请求不是重复提交,拦截器允许请求继续处理。
需要注意的是,这是一个抽象类,isRepeatSubmit 方法是抽象方法,子类需要继承该类并实现具体的重复提交验证规则。
此拦截器可用于在处理请求之前进行重复提交的验证,以避免重复提交表单或重复执行某些操作。它提供了一种通用的机制,可以在不同的请求处理方法上添加 @RepeatSubmit 注解,并通过子类自定义的验证逻辑来实现具体的防重复提交策略。
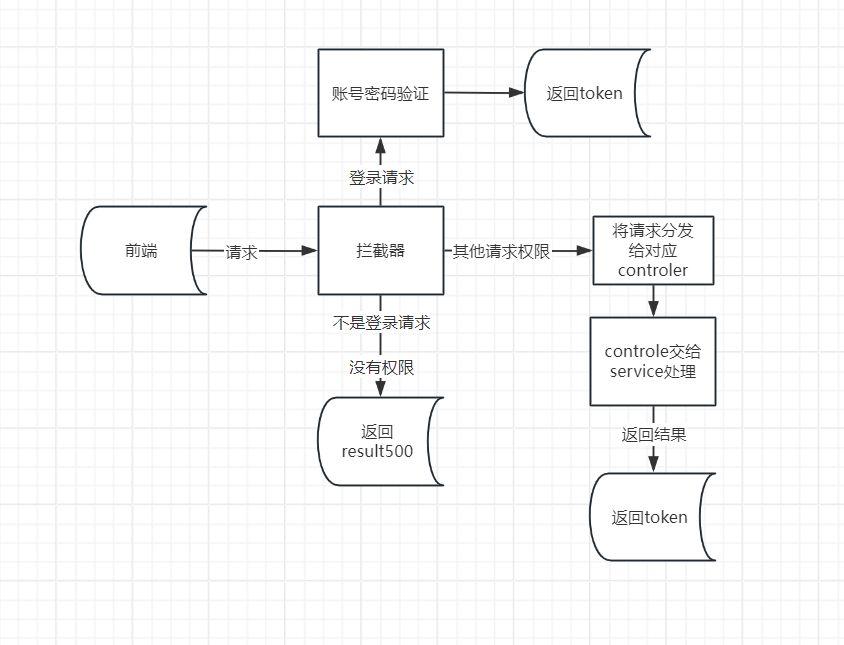
登录请求的模块 这是接下来的步骤
再到controler 控制器
后端的登录请求的功能实现在src/main/java/makeup/web/controller/system/SysLoginController.java
1 | package makeup.web.controller.system; |
这段代码是一个 SysLoginController 类,使用了 @RestController 注解,表示它是一个控制器类,并且该类中的方法返回的是 JSON 数据。
该类中包含以下方法:
-
login方法:使用@PostMapping注解,映射了 “/login” 路径的 POST 请求。该方法接收一个LoginBody对象作为请求体,并返回一个AjaxResult对象作为响应结果。该方法用于处理用户登录请求,并返回登录结果和生成的令牌(token)。 -
getInfo方法:使用@GetMapping注解,映射了 “/getInfo” 路径的 GET 请求。该方法不接收任何参数,返回一个AjaxResult对象作为响应结果。该方法用于获取当前登录用户的信息,包括用户信息、角色集合和权限集合。 -
getRouters方法:使用@GetMapping注解,映射了 “/getRouters” 路径的 GET 请求。该方法不接收任何参数,返回一个AjaxResult对象作为响应结果。该方法用于获取当前登录用户的路由信息,即菜单信息,返回的菜单数据经过处理后构建成路由的格式。
在该类中,使用了 @Autowired 注解对 SysLoginService、ISysMenuService 和 SysPermissionService 进行自动注入,这些服务类可以在方法中被调用。
该类的目的是处理用户登录、获取用户信息和获取路由信息的请求,并返回相应的结果。这些方法通过调用相应的服务类来实现业务逻辑,并将结果封装成 AjaxResult 对象返回给客户端。
再到业务层Service
注意springboot 的业务逻辑一般是写在service中的
所以你需要进入到服务层查看具体的代码
在src/main/java/makeup/framework/web/service/SysLoginService.java
1 | package makeup.framework.web.service; |
这段代码是一个 SysLoginService 类,用于处理用户登录相关的业务逻辑。
这段代码是一个用于用户登录验证的服务类 SysLoginService。它包含了一些方法用于处理用户登录的不同方面。
-
login方法:该方法用于验证用户登录。它接收用户名、密码、验证码和唯一标识作为参数,并返回一个生成的令牌(token)。在方法中,首先进行验证码校验,如果验证码功能启用,会从缓存中获取验证码并与用户输入的验证码进行比对。如果验证码过期或不匹配,将抛出相应的异常。接下来,该方法会进行登录前置校验,包括检查用户名和密码是否为空,以及长度是否符合要求。如果校验未通过,将抛出相应的异常。然后,使用AuthenticationManager进行用户验证。如果验证失败,会记录登录失败的日志并抛出用户密码不匹配的异常。如果验证成功,将记录登录成功的日志信息,并调用recordLoginInfo方法记录用户的登录信息。最后,通过调用tokenService的createToken方法生成令牌,并将其返回给调用方。 -
validateCaptcha方法:该方法用于校验验证码。它接收用户名、验证码和唯一标识作为参数。首先从缓存中获取与唯一标识相关联的验证码,并与用户输入的验证码进行比对。如果验证码过期或不匹配,将抛出相应的异常。如果验证码校验功能未启用,则不会进行验证码校验。 -
loginPreCheck方法:该方法用于进行登录前置校验。它接收用户名和密码作为参数。首先检查用户名和密码是否为空,如果为空,将抛出用户不存在的异常。然后检查密码和用户名的长度是否符合要求,如果不符合要求,将抛出用户密码不匹配的异常。接下来,该方法会检查用户的 IP 是否在黑名单中,如果是,则抛出黑名单异常。 -
recordLoginInfo方法:该方法用于记录用户的登录信息。它接收用户ID作为参数,并根据用户ID获取用户信息。然后,将用户的登录IP和登录时间记录在用户信息中,并通过调用userService的updateUserProfile方法将更新后的用户信息保存到数据库中。
该类使用了 @Autowired 和 @Resource 注解对依赖的服务和组件进行自动注入,包括 TokenService、AuthenticationManager、RedisCache、ISysUserService 和 ISysConfigService 等。这些服务和组件提供了用户登录验证所需的功能,例如生成令牌、用户认证、缓存操作等。
总体而言,SysLoginService 类实现了用户登录验证的逻辑,包括验证码校验、登录前置校验、用户认证、记录登录信息和生成令牌等功能。它与其他服务类和组件协同工作,提供了完整的用户登录验证流程。
最后到数据库redis mysql
比如你看这里的就使用lrediscache
在src/main/java/makeup/common/core/redis/RedisCache.java
1 | package makeup.common.core.redis; |
这段代码是一个名为RedisCache的实用类,它使用Spring Data Redis库提供了与Redis缓存交互的各种方法。让我们简单介绍一下这段代码的功能:
-
setCacheObject:该方法允许你缓存基本对象,如整数、字符串或任何其他实体类。它会将给定键的值设置到Redis缓存中。 -
setCacheObject(带超时):该方法与前一个方法类似,但它还允许你为缓存对象指定超时时间。在指定的超时时间后,对象将自动过期并从缓存中删除。 -
expire:该方法设置Redis缓存中键的过期时间。你可以指定超时值和时间单位(例如秒、分钟等)。如果成功设置了过期时间,则返回true。 -
getExpire:该方法返回Redis缓存中键的剩余存活时间(过期时间)。 -
hasKey:该方法检查Redis缓存中是否存在某个键。如果键存在,则返回true;否则返回false。 -
getCacheObject:该方法根据给定的键从Redis缓存中检索缓存的对象。 -
deleteObject:该方法根据给定的键从Redis缓存中删除单个对象。 -
deleteObject(集合):该方法根据给定的键集合从Redis缓存中删除多个对象。 -
setCacheList:该方法将一个对象列表缓存到与给定键相关联的Redis缓存中。它返回添加到列表中的对象数量。 -
getCacheList:该方法根据给定的键从Redis缓存中检索缓存的对象列表。 -
setCacheSet:该方法将一个对象集合缓存到与给定键相关联的Redis缓存中。它返回与键相关的缓存数据对象。 -
getCacheSet:该方法根据给定的键从Redis缓存中检索缓存的集合对象。 -
setCacheMap:该方法将一个Map缓存到与给定键相关联的Redis缓存中。 -
getCacheMap:该方法根据给定的键从Redis缓存中检索缓存的Map对象。 -
setCacheMapValue:该方法将数据存储到Redis缓存的哈希表中。 -
getCacheMapValue:该方法从Redis缓存的哈希表中获取数据。 -
getMultiCacheMapValue:该方法从Redis缓存的哈希表中获取多个数据。 -
deleteCacheMapValue:该方法从Redis缓存的哈希表中删除某个数据。 -
keys:该方法根据给定的模式获取Redis缓存中的键集合。
总之,这段代码封装了一些常用的Redis缓存操作方法,方便在Spring应用中进行缓存操作。
在上面的代码中,Redis的作用是作为缓存存储。它提供了一种快速、可扩展的方式来存储和获取数据,以减少对后端数据源(例如数据库)的访问。
具体来说,RedisCache类中的各个方法利用Spring Data Redis库与Redis缓存进行交互,实现了以下功能:
-
setCacheObject和setCacheObject(带超时)方法用于将对象缓存到Redis中。这可以提高后续对该对象的读取速度,避免重复计算或数据库查询。 -
expire方法设置Redis缓存中键的过期时间。通过设置过期时间,可以确保缓存数据在一段时间后自动过期,从而避免缓存过时或占用过多内存。 -
getCacheObject方法用于从Redis缓存中获取缓存的对象。如果缓存中存在该对象,则可以直接从Redis中获取,而无需执行其他操作。 -
deleteObject和deleteObject(集合)方法用于从Redis缓存中删除对象。当数据发生变化或不再需要缓存时,可以使用这些方法清除缓存数据。 -
setCacheList和getCacheList方法用于缓存和获取列表对象。这可以在需要缓存一组相关数据时使用,例如最新的文章列表或用户的历史记录。 -
setCacheSet和getCacheSet方法用于缓存和获取集合对象。这可以用于存储唯一值的集合,如用户的标签或商品的分类。 -
setCacheMap、getCacheMap、setCacheMapValue、getCacheMapValue、getMultiCacheMapValue和deleteCacheMapValue方法用于缓存和获取哈希表对象。这可以用于存储和查询具有键值对结构的数据。
通过使用Redis作为缓存存储,可以大大提高应用程序的性能和响应速度,减轻后端数据源的负载,并提供更好的用户体验。
没有看到调用mysql是不是因为这个项目使用了UsernamePasswordAuthenticationToken
UsernamePasswordAuthenticationToken是Spring Security框架中的一个类,用于表示基于用户名和密码的身份认证信息。
在身份验证过程中,用户通常会提供用户名和密码作为凭据进行认证。UsernamePasswordAuthenticationToken就是用来封装这些凭据信息的。
它是AbstractAuthenticationToken类的子类,该类提供了身份验证相关的基本功能。UsernamePasswordAuthenticationToken包含以下属性:
principal:表示身份验证的主体,通常是用户名或用户对象。credentials:表示凭据,通常是用户提供的密码或其他认证信息。authorities:表示用户的权限列表,通常是用户具有的角色或权限。
UsernamePasswordAuthenticationToken对象可以在身份验证过程中进行传递和处理,以便在认证提供者(AuthenticationProvider)中进行验证和授权操作。
在Spring Security的配置中,可以通过配置适当的AuthenticationProvider来处理UsernamePasswordAuthenticationToken对象,并根据提供的用户名和密码进行身份验证和授权操作。


