
这篇论文《CharacterGen: Efficient 3D Character Generation from Single Images with Multi-View Pose Canonicalization》提出了一种高效的方法,可以从单张2D图像生成高质量、可动画化的3D角色模型。以下是论文的核心内容总结:
研究目标
解决从单张图像生成3D角色模型中的关键挑战,包括:
- 姿态复杂性(如自遮挡、姿态歧义)
- 外观一致性(多视图间)
- 下游任务适配性(如绑定、动画)
核心贡献
-
提出CharacterGen框架:
- 输入:任意姿态的单张角色图像
- 输出:标准“A-pose”下的高质量3D角色模型(含纹理)
- 特点:适合直接用于绑定与动画制作

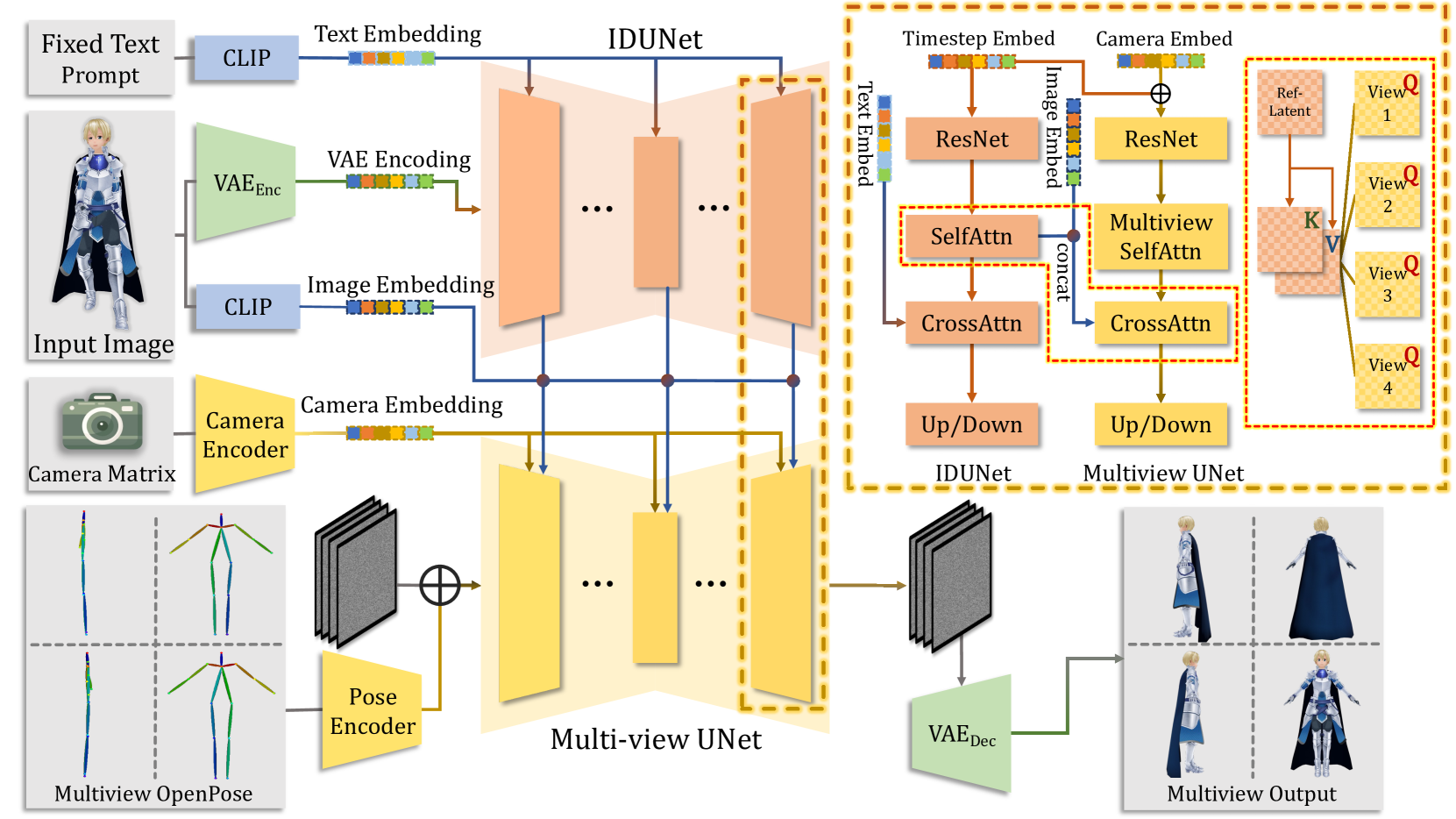
用于生成一致图像的四个视图的管道,展示我们的 IDUNet 如何提取局部像素级特征以加强多视图 UNet。 这里的“Q”、“K”和“V”表示注意力机制中的查询、键和值矩阵。
-
多视图扩散模型(Multi-view Diffusion):
- 引入IDUNet:提取输入图像的像素级特征,增强多视图一致性
IDUNet 是论文 CharacterGen 中提出的一个条件特征提取网络,全称为 Image Detail UNet(根据功能命名,非官方缩写),其核心作用是从输入的角色图像中提取像素级的外观特征,并用于指导后续的多视图扩散模型生成一致的角色图像。
| 模块/机制 | 说明 |
| -------- | ----------------------------------------------------- |
| 结构 | 与主扩散模型(Multi-view UNet)结构相同,类似于 ControlNet 的设计 |
| 输入 | 无噪声的原始图像(通过 VAE 编码) |
| 输出 | 像素级图像特征,用于与扩散模型中的潜变量进行交叉注意力交互 |
| 交互方式 | 通过 Cross-Attention 机制,将输入图像的 patch 级特征注入到多视图生成过程中 |
| 优势 | 保留细节、增强多视图一致性、避免全局特征压缩带来的信息丢失 |- 引入姿态嵌入网络:帮助模型理解角色结构,实现姿态标准化(canonicalization)
- 输出:四视图(前后左右)一致的A-pose图像
- 引入IDUNet:提取输入图像的像素级特征,增强多视图一致性
-
Transformer稀疏视图重建模型:
- 从四视图图像中重建3D几何与粗纹理
- 使用SDF(符号距离函数)提升几何质量
- 支持从NeRF到SDF的两阶段训练
-
纹理优化策略:
- 利用四视图图像进行纹理反投影(back-projection)
- 使用**泊松融合(Poisson Blending)**减少纹理缝隙
-
构建Anime3D数据集:
- 包含13,746个动漫风格角色
- 多姿态、多视角渲染,用于训练与评估
Anime3D 是一个大规模、多姿态、多视角、动漫风格的角色数据集,专为训练从单张图像生成标准化3D角色的模型而构建,具有高度的任务针对性和训练价值。
实验结果
- 2D多视图生成质量优于现有方法(如Zero123、SyncDreamer、IP-Adapter)
- 3D几何与纹理质量优于Magic123、ImageDream、TeCH等方法
- 生成速度快:单角色生成时间约为1分钟,远快于其他方法(如TeCH需270分钟)
- 用户研究显示:在风格一致性、几何质量、纹理质量等方面,用户显著偏好CharacterGen
局限与未来方向
- 极端姿态或非典型视角下,生成效果可能下降
- 当前聚焦于动漫风格角色,未来可扩展至真人或更复杂风格
- 可引入非真实感渲染(NPR)技术进一步提升纹理质量
- 可结合SDS优化提升几何细节
总结
CharacterGen是一个高效、实用、端到端的单图像3D角色生成系统,结合了扩散模型、Transformer重建、纹理优化等多项技术,显著提升了生成质量与速度,为3D内容创作、虚拟人、游戏开发等应用提供了强有力的工具。


